Pop hated not fighting in The War. So he re-enlisted even though he had already served in the Coastal Artillery. Grandma wrote on the back of this picture… “Pvt Allen H. Searls, 42103538, Camp Croft, S.C., Spartanburg, March 1, 1944.” He was promoted to corporal thanks to having served once already, and assigned to the Signal Corps in part because he scored 159 on the Army’s IQ test. He never bragged on that, by the way. (Though I will.) It was also very hard to get it out of him. Not that we needed to. We all knew how smart he was.
Among other things he—
Arrived in the second wave at Normandy.
Lost some of his hearing from laying communications wiring forward of cannons, as his unit advanced.
Was involved in liberating at least one concentration camp.
Served as one of Eisenhower’s phone operators after the war ended.
Like most veterans who were involved in combat and other unpleasantries, he didn’t like talking about that. Instead he talked about his buddies and interesting technical details about how things worked, places he enjoyed seeing.
Maybe my sister (another veteran, in this case of the U.S. Navy) can weigh in with some other details.
Main thing is honoring Pop. He was a great patriot and a great dad.
On a mailing list that obsesses about All Things Networking, another member cited what he called “the Doc Searls approach” to something. Since it was a little off (though kind and well-intended), I responded with this (lightly edited):
The Doc Searls approach is to put as much agency as possible in the hands of individuals first, and self-organized groups of individuals second. In other words, equip demand to engage and drive supply on customers’ own terms and in their own ways.
This is supported by the wide-open design of TCP/IP in the first place, which at least models (even if providers don’t fully give us) an Archimedean place to stand, and a wide-open market for levers that help us move the world—one in which the practical distance between everyone and everything rounds to zero.
To me this is a greenfield that has been mostly fallow for the duration. There are exceptions (and encouraging those is my personal mission), but mostly what we live with are industrial age models that assume from the start that the most leveraged agency is central, and that all the most useful intelligence (lately with AI and ML being the most hyper-focused on and fantasized about) should naturally be isolated inside corporate giants with immense data holdings and compute factories.
Government oversight of these giants and what they do is nigh unthinkable, much less do-able. While regulators aplenty know and investigate the workings of oil refineries and nuclear power plants, there are no equivalents for Google’s, Facebook’s or Amazon’s vast refineries of data and plants doing AI, ML and much more. All the expertise is working for those companies or selling their skills in the marketplace. (The public minded work in universities, I suppose.) I don’t lament this, by the way. I just note that it pretty much can’t happen.
More importantly, we have seen, over and over, that compute powers of many kinds will be far more leveraged for all when individuals can apply them. We saw that when computing got personal, when the Internet gave everybody a place to operate on a common network that spanned the world, and when both could fit in a hand-held rectangle.
The ability for each of us to not only drive prices individually, but to retrieve the virtues of the bazaar to the networked marketplace, will eventually win out. In the meantime it appears the best we can do is imagine that the full graces of computing and networks are what only big companies can do for (and to) us.
My given name is David. Family members still call me that. Or Dave. Everybody else calls me Doc. Since people often ask me where that nickname came from, and since apparently I haven’t answered it anywhere I can now find online*, here’s the story.
Thousands of years ago, in the mid-1970s, I worked at a little radio station owned by Duke University called WDBS. A nice history of the station survives, in instant-loading 1st generation html, here. WDBS veterans, who are many, owe a giant hat tip to Bob Chapman for talking Duke into buying the station in 1971, when he was still a student there. (Try doing that, average undergrad.)
As signals went, WDBS was a shrub among redwoods: strong in Duke’s corner of Durham, a bit weak in Chapel Hill, and barely audible in Raleigh—the three corners of North Carolina’s Research Triangle. (One of those redwoods, WRAL, was audible, its slogan bragged, “from Hatteras to Hickory,” a circle 350 miles wide.)
As a commercial station, WDBS had to sell advertising. This proved so difficult that we made up ads for stuff that didn’t exist. That, in addition to selling ads, was my job. The announcer’s name I used for many of our fake ads, plus other humorous features, was Doctor Dave. It wasn’t a name I chose. Bob Conroy did that. I also had a humorous column under the same name for the station’s monthly arts guide, with the image above at the top of the page. That image was created by Ray Simone, who later became a business partner.
After leaving the station (but while still writing and performing as Doctor Dave) I was hired by Ray and David Hodskins (both devoted WDBS listeners) to write advertising copy for their small “multiple media studio,” which morphed into Hodskins Simone & Searls (aka HS&S), an advertising agency. Since two of us were named David, and Hodskins was especially insistent on using that name (even though his actual forename, I learned years later, was Paul), everybody at the agency called me Doctor Dave, which wore down to Doc. Since my social network in business was larger than all my other circles, the name stuck.
I did see a chance to go back to David when I moved west to prospect for business in Silicon Valley. Early in that work, I market-tested David vs. Doc when I attended my first COMDEX in Las Vegas. I had two badges made, one with Doc Searls and the other with David Searls, and wore each on two of my four days there. Afterward, nobody remembered David, and everybody remembered Doc. So the nickname stuck, especially since my prospecting for business worked out. Within a year, we became one of Silicon Valley’s hottest ad agencies and closed our North Carolina office.
The nickname survives. Alas, HS&S was sold to Publicis in 1999, Ray died in 2011, and David in 2022. I don’t miss the ad biz, but I do miss Ray and David, both gone way too soon.
For an example of Doctor Dave’s output, see the TV Guide listings parody here.
*[Later…] Or couldn’t at the time. Hanan Cohen, below, finds a post from 2009 that visits the nickname’s origin story.
Nobody is going to own podcasting. By that I mean nobody is going to trap it in a silo. Apple tried, first with its podcasting feature in iTunes, and again with its Podcasts app. Others have tried as well. None of them have succeeded, or will ever succeed, for the same reason nobody has ever owned the human voice, or ever will. (Other, of course, than their own.)
Because podcasting is about the human voice. It’s humans talking to humans: voices to ears and voices to voices—because listeners can talk too. They can speak back. And forward. Lots of ways.
Podcasting is one way for markets to have conversations; but the podcast market itself can’t be bought or controlled, because it’s not a market. Or an “industry.” Instead, like the Web, email and other graces of open protocols on the open Internet, podcasting is all-the-way deep.
Deep like, say, language. And, like language, it’s NEA: Nobody owns it, Everybody can use it and Anybody can improve it. That means anybody and everybody can do wherever they want with it. It’s theirs—and nobody’s—for the taking.
Both of those are tools created by Dave Winer, alpha dad of blogging, podcasting and syndicating. Dave was half the guests on Friday evening’s opening panel. The other half was Christopher Lydon, whose own podcast, Radio Open Source, was born out of his creative partnership with Dave in the early chapters of podcasting’s Genesis, in 2003, when both were at Harvard’s Berkman (now Berkman Klein) Center.
One way you can tell nobody owns podcasting is that 1.5 decades have passed since 2003 and there are still no dominant or silo’d tools either for listening to podcasts or for making them.
On the listening side, there is no equivalent of, say, the browser. There are many very different ways to get podcasts, and all of them are wildly different as well. Remarkably (or perhaps not), the BigCo leaders aren’t leading. Instead they’re looking brain-dead.
The biggest example is Apple, which demonstrates its tin head through its confusing (and sales-pressure-intensive) iTunes app on computers and its Podcasts app, defaulted on the world’s billion iPhones. That app’s latest version is sadly and stupidly rigged to favor streaming from the cloud over playing already-downloaded podcasts, meaning you can no longer listen easily when you’re offline, such as when you’re on a plane. By making that change, Apple treated a feature of podcasting as a bug. Also dumb: a new UI element—a little set of vertical bars indicating audio activity—that seems to mean both live playing and downloading. Or perhaps neither. I almost don’t want to know at this point, since I have come to hate the app so much.
Other tools by smaller developers (e.g. Overcast) do retain the already-downloaded feature, but work in different ways from other tools. Which is cool to me, because that way no one player dominates.
On the production side there are also dozens of tools and services. As a wannabe podcaster (whose existing output is limited so far to three podcasts in twelve years), I have found none that make producing a podcast as easy as it is to write a blog or an email. (When that happens, watch out.)
So here’s a brief compilation of my gatherings, so far, in no order of importance, from the conference.
Podcasting needs an unconference like IIW (the next of which happens the first week of May in Silicon Valley): one devoted to conversation and forward movement of the whole field, and not to showcasing panels, keynotes or sponsoring vendors. One advantage of unconferences is that they’re all about what are side conversations at standard keynote-and-panel conferences. An example from my notes: Good side conversations. One is with Sovana Bailey McLain (@solartsnyc), whose podcast is also a radio show, State of the Arts. And she has a blog too. The station she’s on is WBAI, which has gone through (says Wikipedia) turmoil and change for many decades. An unconference will also foster something many people at the conference said they wanted: more ways to collaborate.
Now is a good time to start selling off over-the-air radio signals. Again from my notes… So I have an idea. It’s one WBAI won’t like, but it’s a good one: Sell the broadcast license, keep everything else. WBAI’s signal on 99.5fm is a commercial one, because it’s on the commercial part of the FM band. This NY Times report says an equivalent station (WQXR when it was on 96.3fm) was worth $45 million in 2009. I’m guessing that WBAI’s licence would bring about half that because listening is moving to Net-connected rectangles, and the competition is every other ‘cast in the world. Even the “station” convention is antique. On the Net there are streams and files:stuff that’s live and stuff that’s not. From everywhere. WBAI (or its parent, the Pacifica Foundation), should sell the license while the market is still there, and use the money to fund development and production of independent streams and podcasts, in many new ways. Keep calling the convening tent WBAI, but operate outside the constraints of limited signal range and FCC rules.
Compared to #podcasting, the conventions of radio are extremely limiting. You don’t need a license to podcast. You aren’t left out of the finite number of radio channels and confined geographies. You aren’t constrained by FCC anti-“profanity” rules limiting freedom of speech—or any FCC rules at all. In other words, you can say what the fuck you please, however you want to say it. You’re free of the tyranny of the clock, of signposting, of the need for breaks, and other broadcast conventions. All that said, podcasting can, and does, improve radio as well. This was a great point made on stage by the @kitchensisters.
Podcasting conventionally copyrighted music is still impossible. On the plus side, there is no license-issuing or controlling entity to do a deal with the recording industry to allow music on podcasts, because there is nothing close to a podcasting monopoly. (Apple could probably make such a deal if it wanted to, but it hasn’t, and probably won’t.) On the minus side, you need to “clear rights” for every piece of music you play that isn’t “podsafe.” That includes nearly all the music you already know. But then, back on the plus side, this means podcasting is nearly all spoken word. In the past I thought this was a curse. Now I think it’s a grace.
Today’s podcasting conventions are provisional and temporary. A number of times during the conference I observed that the sound coming from the stage was one normalized by This American Life and its descendants. In consonance with that, somebody put up a slide of a tweet by @emilybell:podcast genres : 1. Men going on about things. 2. Whispery crime 3.Millennials talking over each other 4. Should be 20 minutes shorter. We can, and will, do better. And other.
Maybe podcasting is the best way we have to start working out our problems with race, gender, politics and bad habits of culture that make us unhappy and thwart progress of all kinds. I say that because 1) the best podcasting I know deals with these things directly and far more constructively than anything I have witnessed in other media, and 2) no bigfoot controls it.
Archiving is an issue. I don’t know what a “popup archive” is, but it got mentioned more than once.
Podcasting has no business model. It’s like the Internet, email and the Web that way. You make money because of it, not with it. If you want to. Since it can be so cheap to do (in terms of both time and money), you don’t have to make money at it if you don’t want to.
I’ll think of more as I go over more of my notes. Meanwhile, please also dig Dave’s take-aways from the same conference.
I’ve hated rating people ever since I first encountered the practice. That was where everybody else does too: in school.
After all, rating people is what schools do, with tests and teachers’ evaluations. They do it because they need to sort students into castes. What’s school without a bell curve?
As John Taylor Gatto put it in the Seven Lesson Schoolteacher, the job of the educator in our industrialized education system is to teach these things, regardless of curricular aspirations or outcomes:
confusion
class position
indifference
emotional dependency
intellectual dependency
provisional self-esteem
that you can’t hide
It’s no different in machine-run “social sharing” systems such as we get from Uber, Lyft and Airbnb. In all those systems we are asked to rate the people who share their cars and homes, and they are asked to rate us. The hidden agenda behind this practice is the same as the one Gatto describes above.
I bring this up because yesterday my wife and I had our first less-than-ideal shared ride. To spare everyone involved, I won’t say whether it was with Uber or Lyft, or where the ride went. I will say the ride is normally around half an hour, and we’ve taken the same ride dozens of times.
First, the driver didn’t help us load our two heavy bags into the trunk of his car, which had a lot of loose crap in it.(And, to be fair, lots of shared-ride drivers have a collection of their own stuff in the trunk.) Maybe he declined because there was heavy traffic and we all needed to get a move on, or he didn’t see the bags; but let’s just say that wasn’t normal, or what drivers usually do when picking up people with sizable luggage.
Soon as we were on the road, he asked if we’d mind if he stopped at an ATM, because he needed money for tolls. Seems his EZ-Pass transponder had a problem and needed to be sent in and exchanged, so he was operating without it. We said okay and took a slow parallel highway where he hoped an ATM could be found. He eventually found one at a gas station mini-mart, but the machine had a problem that took about 20 minutes, during which we just sat in the car.
After he got the money, we found our way back to the main toll road, and eventually to our destination. At one point on the toll road I reminded him that he should get a receipt for the toll he paid in cash. At our destination he did get out of the car to help with our bags, but I had already removed them from the trunk.
The whole ride took an hour and thirty two minutes, according to the Moves app on my phone. Since it was rush hour, I’d say the ride took about 45 minutes longer than it should have.
So that’s the down side.
The upside was that he seemed to be a genuinely good guy, trying to make a living and dealing with the world. He recently moved into the area to seek work as a recording engineer: a skill he learned recently at a trade school after tiring of an earlier career as a technician for a mobile phone company. His wife is pregnant with their first child, and they are struggling to make ends meet, which is why he was felt he had to work giving rides, even though he lacked two essential conveniences: an EZ-Pass or enough cash.
He had a lot of interesting things to say about working for Uber and Lyft (he drives for both), what makes a good or a bad ride (he’s had both as a passenger), and whether telling the story of their coming baby would make a good YouTube mini-documentary or podcast. We also talked about history, architecture, culture and travel. He speaks Spanish as well as English and would like to go to Spain someday. He also apologized for the delays, and thanked me for understanding his situation. (Or situations.) And I gave him a tip. (Which I always do, at least in the U.S.)
So, while the ride itself wasn’t great, the conversation was one of the better ones I’ve had with a driver. And I wanted to support the guy’s work.
But I couldn’t not rate the guy, or I wouldn’t be able to get a receipt or book the next ride. So I gave him four stars out of five. That’s the first time I’ve given any driver less than five stars. When I clicked on the fourth star, the app said what you see in the screen shot (from my phone) above. “Okay, could be better” was about right. Still, I would much rather have said nothing—or to have sent a note to the company. Anything but giving the guy some number of stars.*
And no, I don’t know a better way. I am just sure that rating people is icky, and would rather say nothing than stroke or damn somebody with a star.
*Some time after this, Don Marti told me he always gives everyone five stars. “Never betray a human to the machines.” This made me regret knocking a star off that driver’s record.
I shot this picture with my phone on the subway last night, while no less absorbed in my personal rectangle than everyone else on the subway (and I do mean everyone) was with theirs.
I don’t know what the other passengers were doing on their rectangles, though it’s not hard to guess. In my case it was spinning through emails, texting, tweeting, checking various other apps (weather, navigation, calendar) and listening to podcasts.
Two years from now, most of the phones used by people in this shot will be traded in, discarded or re-purposed. But will we remain just as tethered to Apple, Google, Facebook, Amazon, telcos and the other feudal overlords* that sell us our rectangles and connect to the world? (*A metaphor we owe to Bruce Schneier.)
The deeper question is whether we’ll finish becoming dependent serfs to sovereigns with silos or start becoming self-sovereign as free-range human beings in truly open societies.
The answer will probably be some combination of both. In the meantime, however, one clear need is for greater independence and agency, at least at the individual level. (There are similar needs at the social, political and economic spheres as well, but let’s keep this personal.)
Obsolescence will help.
Within the next two years (just like the last two and the two before that), most phones will do less old-fashioned telephony, text, audio and video, and much more cool (and perhaps scary) new shit (VR, AI, IA, CX and other two-letter acronyms, to name a few off the top of my head and my screen).
Just as surely they’ll also give us new ways to shape what we do and be shaped as well. Perhaps by then mass media will finish turning into the mess media it actually is already, though we don’t call it that yet.
One big Hmm is What comes after phone use spreads beyond ubiquity (when most of us have multiple rectangles)?
Everything gets obsolesced, one way or another, eventually. But that doesn’t mean it goes away. It just means something else comes along that’s better for the main purpose, while the obsolesced tech still hangs around in a subordinated, subsumed or specialized state. Print did that to scribing, Radio did that to print, TV did it to radio, and the Net is doing it to damn near every other medium we can name, subsuming them all and stretching their effects to the absolute limit by eliminating the distances between everything while pushing costs toward zero. (See The Giant Zero for more on that.)
Thus, while all our asses still sit on Earth in physical space, our digital selves float weightlessly in a non-space with no gravity and no distance. Since progress is the process by which the miraculous becomes mundane, we already experience these two states non-ironically and all at once. And een this isn’t new. Here’s what I wrote about it in The Intention Economy, published in 2012:
Story #1. It’s 2002, and the kid is seven. As always, he’s full of questions. As sometimes happens, I don’t have an answer. But this time he comes back with a simple demand:
“Look it up,” he says.
“I can’t. I’m driving.”
“Look it up anyway.”
“I need a computer for that.”
“Why?”
Story #2. It’s 2007, and we are staying overnight in the house of an old family friend. In a guest bedroom is a small portable 1970’s-vintage black-and-white TV. On the front of the TV are a volume control and two tuning dials: one for channels 2-13, the other for 14-83. The kid examines the device for a minute or two and says, “What is this?” I say it’s a TV. He points at the two dials and asks, “Then what are these for?”
Progress is how the miraculous becomes mundane. The beauty of stars would be legend, Emerson said, if they only showed through the clouds but once every thousand years. What would he have made of commercial aviation, a system by which millions of people fly all over the globe, every day, leaping continents and oceans in just a few hours, while complaining of bad food and slow service, and shutting their windows to block light from the clouds below so they can watch a third-rate movie with bad sound on a tiny screen?
The Internet is a sky of stars we’ve made for ourselves (and of ourselves), all just a few clicks away.
Mcuhan says the effects of every new medium can be understood through four questions he calls a tetrad, illustrated this way:
Put a new medium in the middle and then sort effects into the four corners by answering a question for each:
What does the medium enhance?
What does the medium make obsolete?
What does the medium retrieve that had been obsolesced earlier?
What does the medium reverse or flip into when pushed to extremes?
These are posed as a heuristic: an approach to help us understand what’s going on, rather than a way to come up with perfect or final answers. There can be many answers to each question, all arguable.
So let’s look at smartphones. I suggest they—
Enhance conversation
Obsolesce mass media (print, radio, TV, cinema, whatever)
Retrieve personal agency (the ability to act with effect in the world)
Reverse into isolation (also into lost privacy through exposure to surveillance and exploitation)
I don’t think we’re all the way into any of those yet, even as every damn one of us in a subway rewires our brains in real time using rectangles that extend our presence, involvement and effects in the world. Ironies abound, invisible, unnoticed. We all smell something. Is it our human frogs boiling? The primordial ooze out of which we are evolving into creatures other than human? What is that?
Here’s a hmm: what will obsolesce smartphones?
I don’t have answers; I’m just sure there will be some—and that we’ll have passed Peak Phone when they come.
Brands are starting to bail from adtech, and news about it is coming fast and hard.
The New York Times said AT&T and Johnson & Johnson were pulling their ads from YouTube, concerned that “Google is not doing enough to prevent brands from appearing next to offensive material, like hate speech.” Business Insider said “more than 250” advertisers were bailing as well. Both reports came on the heels of one Guardian story that said Audi, HSBC, Lloyds, McDonald’s, L’Oréal, Sainsbury’s, Argos, the BBC and Sky were doing the same in the UK. Another Guardian story that said O2, Royal Mail and Vodaphone were joining the boycott as well. Wired and AdAge have weighed in too.
Agencies placing those ads on YouTube were shocked, shocked! that ads for these fine brands were showing up next to “extremist material,” and therefore sponsoring it. They blame Google, and so does most of the press coverage as well.
Google’s executives were summoned to appear in front of the UK government last week after ads for taxpayer-funded services were found next to extremist videos, following an investigation by The Times newspaper. Google must return later this week with a timetable for the work it is doing to prevent the issue from occurring again.
On Monday, at a breakfast briefing with journalists before he took to the stage at Advertising Week Europe — Brittin said the annual ad industry event gave Google a “good opportunity to say first and foremost, sorry, this should not happen, and we need to do better.”
Brittin added: “There are brands who have reached out to us and are talking to our teams about whether they are affected or concerned by this. I have spoken personally to a number of advertisers over the last few days as well. Those that I have spoken to, by the way, we have been talking about a handful of impressions and pennies not pounds of spend — that’s in the case of the ones I’ve spoken to at least. However small or big the issue, it’s an important issue that we address.”
Google also isn’t alone at this. They’re just the biggest player in an icky business. That business is adtech: tracking-based advertising.
Real advertising doesn’t do any of those things, because it’s not personal. It is aimed at populations selected by the media they choose to watch, listen to or read. To reach those people with real ads, you buy space or time on those media. You sponsor those media because those media also have brand value.
With real advertising, you have brands supporting brands.
Brands can’t sponsor media through adtech because adtech isn’t built for that. On the contrary, adtech is built to undermine the brand value of all the media it uses, because it cares about eyeballs more than media.
Adtech is magic in this literal sense: it’s all about misdirection. You think you’re getting one thing while you’re really getting another. It’s why brands think they’re placing ads in media, while the systems they hire chase eyeballs. Since adtech systems are automated and biased toward finding the cheapest ways to hit sought-after eyeballs with ads, some ads show up on unsavory sites. And, let’s face it, even good eyeballs go to bad places.
This is why the media, the UK government, the brands, and even Google are all shocked. They all think adtech is advertising. Which makes sense: it lookslike advertising and gets called advertising. But it is profoundly different in almost every other respect. I explain those differences in Separating Advertising’s Wheat and Chaff:
…advertising today is also digital. That fact makes advertising much more data-driven, tracking-based and personal. Nearly all the buzz and science in advertising today flies around the data-driven, tracking-based stuff generally called adtech. This form of digital advertising has turned into a massive industry, driven by an assumption that the best advertising is also the most targeted, the most real-time, the most data-driven, the most personal — and that old-fashioned brand advertising is hopelessly retro.
In terms of actual value to the marketplace, however, the old-fashioned stuff is wheat and the new-fashioned stuff is chaff. In fact, the chaff was only grafted on recently.
See, adtech did not spring from the loins of Madison Avenue. Instead its direct ancestor is what’s called direct response marketing. Before that, it was called direct mail, or junk mail. In metrics, methods and manners, it is little different from its closest relative, spam.
Direct response marketing has always wanted to get personal, has always been data-driven, has never attracted the creative talent for which Madison Avenue has been rightly famous. Look up best ads of all time and you’ll find nothing but wheat. No direct response or adtech postings, mailings or ad placements on phones or websites.
Yes, brand advertising has always been data-driven too, but the data that mattered was how many people were exposed to an ad, not how many clicked on one — or whether you, personally, did anything.
And yes, a lot of brand advertising is annoying. But at least we know it pays for the TV programs we watch and the publications we read. Wheat-producing advertisers are called “sponsors” for a reason.
So how did direct response marketing get to be called advertising ? By looking the same. Online it’s hardto tell the difference between a wheat ad and a chaff one.
Remember the movie “Invasion of the Body Snatchers?” (Or the remake by the same name?) Same thing here. Madison Avenue fell asleep, direct response marketing ate its brain, and it woke up as an alien replica of itself.
This whole problem wouldn’t exist if the alien replica wasn’t chasing spied-on eyeballs, and if advertisers still sponsored desirable media the old-fashioned way.
Fixing it won’t be easy, because the alien replica has been drunk on digital for so long that very little humanity remains. This is true not just for Madison Avenue, but for both the client and the media stages of the advertising supply chain. On the client side, old-school sales & marketing VPs have been replaced by data-obsessed CMOs who would rather hire an IBM to paint a portrait of a fiction called “the chief executive customer” than actually talk to a real one. On the media side, publishers and broadcasters have long since fired their human sales people and outsourced income production to dozens of third party adtech systems.
But at least we’re seeing brands start to wake up, even if they’re still fooled by adtech’s magic tricks. And consciousness is surely happening a level or two above the CMO. Those senior executives, whose brains have not been snatched by adtech, will still recognize the obvious: that brands are best made and served by sponsoring media they know, like and trust.
After all, sponsoring trusted media is what produced brands in the first place. It’s also what still what makes brands familiar to whole populations, and what still sponsors worthy publications and the journalism they contain.
If brands still want to do “interest-based” or “interactive” advertising (adtech’s euphemisms for what it actually does) they should realize five things:
Adtech sucks at branding. Hundreds of $billions have been spent on adtech so far, and not one brand known to the world has come out of it.
Yes, it works, about .0x% of the time, on average. The other 99.9x% of the time it produces nothing but negative externalities, including lots of tendentious math by agencies and platforms to justify the expense.Among those externalities are subtracted value from brands themselves.
Yes, direct response marketing does work, and it works best when target customers have already opted in, consciously and deliberately. (Note that there is a great deal of ambiguity about how much being a Google or Facebook member amounts to deliberate and conscious agreement to being followed and targeted, privacy controls withstanding. The choices in those controls should be much more binary and clear than they are.) So if L’Oreal wants to get a conversation going with customers of Lancôme, Giorgio Armani or The Body Shop, they should do it by those customers’ grace, not because the robots they’ve hired guess those customers might be interested, based on surveillance-gathered personal data.
Adtech starts with spying on people. This isn’t the elephant in the middle of adtech’s room. It’s the volcano about to erupt from under adtech’s floor. In that volcano are pissed off people who will soon get their own ways to kill off adtech. The rumbling under the floor right now is ad blocking. The lava that will pave over adtech is full tracking protection.
Adtech’s rationalizations are all around putting the “right message in front of the right people at the right time,” and aiming those messages with spyware-harvested Big Data. Both of those are direct marketing purposes, not those of brand advertising. The difference is stark, absolute, and essential for everyone to understand.
The only reason publishers go along with adtech is that they don’t know any other way to make money from advertising online — and no developers have provided them one. (But that will happen soon. Trust me on this. I know things I can’t yet talk about.)
What Shoshana Zuboff calls “surveillance capitalism” is going to be illegal a year from now in the EU anyway, thanks to the General Data Protection Regulation, aka GDPR. Mark your calendars: on 25 May 2018 will come an extinction event for adtech, because here are the fines the GDPR will impose for unpermitted harvesting of personal data: 1) “a fine up to 10,000,000 EUR or up to 2% of the annual worldwide turnover of the preceding financial year in case of an enterprise, whichever is greater (Article 83, Paragraph 4)”‘; and 2) “a fine up to 20,000,000 EUR or up to 4% of the annual worldwide turnover of the preceding financial year in case of an enterprise, whichever is greater (Article 83, Paragraph 5 & 6).”
Ad choices won’t do the job. That’s adtech’s way to “give you control” over “how information about your interests is used for relevant advertising.” The link into that system is this little symbol you see in the corner of many ads:
While clicking on it does provide a way for you to opt out of surveillance, you have to do it over and over again for every ad you see with the damn thing, like playing a slo-mo game of whack-a-mole, and it still relies on the adtech industry keeping cookies in your browsers.
If there is a market on the receiving end for “interest based advertising,” let’s have a standard system that puts full control in the hands of individuals, and speaks through open code and protocols to any and all publishers and broadcasters. Anything less will just be another top-down adtech industry paint-job on the same old shit.
An open question is if agencies can be programmatic online without spying on people. I think they can, if they start by admitting that spying is where the problem lies.
It should be clear that spying is why Do Not Track became a thing, and whyad blocking hockey-sticked when the adtech industry and publishers together gave the middle finger to people’s polite request not to be tracked. (Which is all Do Not Track provides.) It should also be clear that ad blocking and tracking protection are not “threats” and “costs” to publishers and agencies. They are clear and legitimate market responses by human beings to having adtech’s digital hands up their skirts.
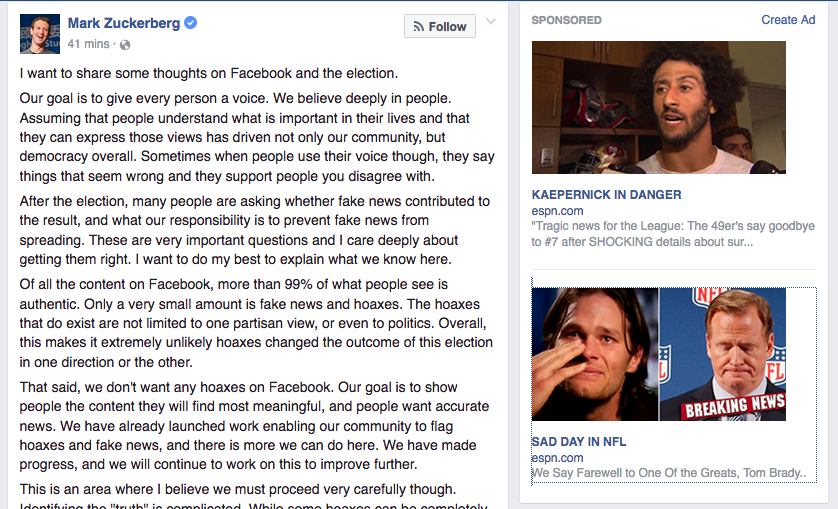
It also won’t be easy for the big platforms to fix their adtech systems. Consider, for example, the egg that was splattered on Mark Zuckerberg’s face by Facebook’s own adtech when he posted his insistence that “99% of what people see is authentic” and “only a very small amount is fake news and hoaxes,” and fraudulent ads ran right next to his post:
These ads are fraudulent in at least three ways: 1) the headlines are lies; 2) espn.com is not the advertiser; 3) if you click on them, you find they’re bait for switches to something else. (One I clicked on was for a diet supplement.)
Facebook is going to have a hard time fixing this, because it is entirely in the chaff business. With Google, even though it’s hard to tell whether any given ad placed in a Google property is wheat or chaff, at least some of it really is wheat. (I would guess most search ads are, for example.) It should be just as easy for Google to disclose those ads’ nature as wheat as it is for the company to use Ad Choices to disclose adn ad’s nature as chaff. (I suggest one possible approach to this in A way to peace in the adblock war.)
But fixing the mess needs to start with advertisers. They can do it by firing adtech and its agents and going back to sponsoring reputable broadcasters and publishers. Simple as that.
I’ve long thought that the most consequential thing I’ve ever done was write a newspaper editorial that helped stop development atop the highest wooded hilltop overlooking the New York metro. The hill is called High Mountain, and it is now home to the High Mountain Park Preserve in Wayne, New Jersey. That’s it above, highlighted by a rectangle on a shot I took from a passenger plane on approach to LaGuardia in 2008.
The editorial was published on October 21, 1970, when I was a 23-year-old reporter for a suburban daily called Wayne Today (which may still exist). One day, while at the police station picking up copies of the previous day’s reports, I found a detailed plan to develop the top of High Mountain, and decided to pay the place a visit. So I took a fun hike through thick woods to a rocky clearing at the crest, and immediately decided the mountain was a much better place for a park than for the office building specified in the plan.
As it happened there was also a need for an editorial soon after that, and Jerry Fuchs, who usually wrote our editorials, wasn’t available. So I came off the bench and wrote this:
That was a draft proof of the piece.* I ran across it today while cleaning old papers from a file cabinet in my garage. I doubt anybody has the final printed piece, and I’m amazed that the proof exists.
I left for another paper after that, and didn’t keep up with Wayne news, beyond hearing that my editorial derailed the development plan. No doubt activists of various kinds were behind the eventual preservation of the mountain. But it’s nice to know there is some small proof I had something to do with that.
*Additional history: Wayne Today published in those days using old-fashioned letterpress techniques. Type was set in lead by skilled operators on Linotype machines. Each line was a “slug,” and every written piece was a pile of slugs arranged in a frame, inked with a roller and then proofed by another roller that printed on blank paper. That’s what we marked up (as you see above) for the Linotype operators, who would create replacement slugs, give them to the page composers in layout, who could read upside down and backwards as they arranged everything in what was called a forme. The layout guys (they were all guys) then embossed each page into a damp papier-mâché sheet, which would serve as a mold for a half-cylinder of hot lead. Half-cylinders wrapped around giant rollers inked each rotation by other rollers did the printing. Other machines after that cut, stacked and folded the pages that ended up as newspapers at the end of the line. So the whole process went like this: reporter->Linotype operator->editor->Linotype operator->page composer->stereotype operator->printer. Ancestors of robotics eventually replaced all of it not long after I left (and the press burned down). Now in the U.S. exemplars of big-J journalism (New York Times, Washington Post) are tarred by the President as “fake news,” and millions believe him. My, how times change.
Emanuele Orazio Fenzi, better known as Francesco Franceschi (1843-1924), was an Italian horticulturist responsible for vastly increasing the botanical variety of Santa Barbara (introducing more than 900 species). He was also for awhile the primary landowner on the Riviera, a loaf-shaped hill overlooking the city’s downtown. Most of that hill is now covered with houses, but a large part that isn’t is what remains of the Franceschi estate: 18 acres called Franceschi Park, featuring a crumbling mansion and the bust above, carved into the top of a boulder on the property.
The city doesn’t have much to say about Franceschi, with a website devoted to the park that goes one paragraph deep. This makes sense, because the state of neglect in the park is extreme. I won’t go into details, because they’re well presented all these stories:
Saving Franceschi’s bust is surely an easier job than saving his house. What I’m hoping here is that publishing this blog post will stir up some interest.
Before we start, let me explain that ATSC 1.0 is the HDTV standard, and defines what you get from HDTV stations over the air and cable. It dates from the last millennium. Resolution currently maxes out at 1080i, which fails to take advantage even the lowest-end HDTVs sold today, which are 1080p (better than 1080i).
Your new 4K TV or computer screen has 4x the resolution and “upscales” the ATSC picture it gets over the air or from cable. But actual 4k video looks better. The main sources for that are the on-demand subscription streaming services, currently led by Netflix. All the sources of video “content” (Disney, Paramount, the TV networks) are headed into the same business, which together are called OTT, for Over The Top.
In other words, broadcast TV is to 4K streaming what AM radio is to FM. (Or what both are to audio streaming and podcasting.)
New FCC chairman Ajit Pai signaled Thursday that he wants broadcasters to be able to start working on tomorrow’s TV today.
Pai, who has only been in the job since Jan. 20, wasted no time prioritizing that goal. He has already circulated a Notice of Proposed Rulemaking to the other commissioners that would allow TV stations to start rolling out the ATSC 3.0 advanced TV transmission standard on a voluntary basis. He hopes to issue final authorization for the new standard by the end of the year, he said in an op ed in B&C explaining the importance of the initiative.
“Next Gen TV matters because it will let broadcasters offer much better services in a variety of ways,” Pai wrote. “Picture quality will improve with 4K transmissions. Accurate sound localization and customizable sound mixes will produce an immersive audio experience. Broadcasters will be able to provide advanced emergency alerts with more information, more tailored to a viewer’s particular location. Enhanced personalization and interactivity will enable better audience measurement, which in turn will make for higher-quality advertising—ads relevant to you and that you actually might want to see. Perhaps most significantly, consumers will easily be able to watch over-the-air programming on mobile devices.”
How does this square with the Incentive Auction, which—if it succeeds—will make over-the-air (OTA) TV little more than a requirement for “must-carry” on cable?
What will this do for (or against) cable and satellite TV, which is having a helluva time wedging too many channels into its available capacities already, and do it by compressing the crap out of everything, filling the screen with artifacts (those sections of skin or ball fields that look plaid or pixelated)?
I think over-the-air (OTA) and cable TV are dead horses walking, and ATSC 3.0 won’t save them. Worse, it is likely that ATSC 3.0 won’t be old-fashioned free OTA TV. It will require a subscription, making OTA even more dead. We’ll still have cable, but will use it mostly to watch and interact with streams, many of which will come from producers and distributors that were Net-native in the first place. And very little of it will be 4K or better.
But I could be wrong about any or all of this. Either way (or however), tell me how.
[Update on 9 April 2022…] All the antennas flanking the art deco face of the Empire State Building in the photo above are now removed. So are the T-shaped antennas above and below the 102nd floor observation level, to make room for taller windows. The “rototiller” FM antenna is gone, along with some of the antennas above it. Some of those have been replaced. The long-abandoned channel 4 and 5 “batwing” antenna at the very top remains, serving by default a decorative purpose. Meanwhile, a fence of taller buildings have gone up along 57th Street to the north between Broadway and Park Avenue, no doubt affecting signals from the Empire State Building to some degree. But caring about FM reception is on the decline, as listening and viewing continue to drift from live broadcasts to streams and podcasts accessed on demand, over the Net rather than over the air.
Journalism is in a world of hurt because it has been marginalized by a new business model that requires maximizing “content” instead. That model is called adtech.
We can see adtech’s effects in The New York Times’ In New Jersey, Only a Few Media Watchdogs Are Left, by David Chen. His prime example is the Newark Star-Ledger, “which almost halved its newsroom eight years ago,” and “has mutated into a digital media company requiring most reporters to reach an ever-increasing quota of page views as part of their compensation.”
That quota is to attract adtech placements.
While adtech is called advertising and looks like advertising, it’s actually a breed of direct marketing, which is a cousin of spam and descended from what we still call junk mail.
Like junk mail, adtech is driven by data, intrusively personal, looking for success in tiny-percentage responses, and oblivious to harms it causes, which include wanton and unwelcome surveillance, annoying the shit out of people and filling the world with crap.
But adtech is far worse, because it also funds hyper-partisan news flows, including vast rivers of fake news, much of it from pop-up publishers that are as fake as the clickbait they maximize. Without adtech, fake news would be marginalized to the digital equivalent of supermarket tabloids.
Here’s one way to tell the difference between real advertising and adtech:
Real advertising wants to be in a publication because it values the publication’s journalism and readership.
Adtech wants to push ads at readers anywhere it can find them.
Here’s one way to tell the difference between journalism and content:
Journalism has ethics.
Content has volume.
Another:
Journalism is supported by advertising and subscriptions.
Content is supported by adtech.
Companies advertising in the old publishing world were flattered to appear in publications like the Star-Ledger. They were also considered sponsors of those publications.
Companies advertising in the new publishing world are drunk on digital and want to maximize the “big data” they acquire. And there are thousands of bartenders to help with that.
As I wrote in Separating Advertising’s Wheat and Chaff, in the new publishing world “Madison Avenue fell asleep, direct response marketing ate its brain, and it woke up as an alien replica of itself.”
That’s also why, to operate in publishing’s new alien-built economy, journalists need to meet that “ever-increasing quota of page views.” Better to “generate content” than to do the best journalism we can, the proposition goes. It’s still a losing one.
See, adtech doesn’t care about journalism, because its economy incentives maximizing the sum of content in the world, so it has as many places as possible to chase followed eyeballs with ads. Case in point, from @WaltMossberg:
About a week after our launch, I was seated at a dinner next to a major advertising executive. He complimented me on our new site’s quality and on that of a predecessor site we had created and run, AllThingsD.com. I asked him if that meant he’d be placing ads on our fledgling site. He said yes, he’d do that for a little while. And then, after the cookies he placed on Recode helped him to track our desirable audience around the web, his agency would begin removing the ads and placing them on cheaper sites our readers also happened to visit. In other words, our quality journalism was, to him, nothing more than a lead generator for target-rich readers, and would ultimately benefit sites that might care less about quality.
If Recode insisted on real ads, rather than coming to depend on surveillance-based adtech, its advertisers would have valued the publication, and not just the eyeballs of its readers, wherever it could find them.
Walt concludes,
It’s no easy task to either make money online as a publisher or to advertise your product in a world where attention is so fleeting and divided. But the current system of ad-supported web content isn’t working for readers and viewers. It needs to be reset.
The ad business is too brain-snatched to do that reset alone. It needs help from readers and brave publishers willing to stop participating in the adtech game.
As I explain in How customers can debug business with one line of code (hashtag: #NoStalking), each of us can come to publishers with a simple term that says “Just show me ads not based on tracking me.” In other words, “Give us real advertising. We can live with that.”
#NoStalking is not only in the works at Customer Commons, but saying yes to it will be an ideal move by companies wishing to obey the General Data Protection Regulation (aka GDPR), which will start punishing stalking severely, starting in 2018.
While the GDPR will blow up adtech as we’ve known it, #NoStalking will save real advertising, and the best of ad-supported publishing along with it, because it will bring economic incentives back into alignment with journalism. We had that in the old ad-and-subscription supported world of offline journalism, and we can get it back in the new world of online journalism. As I explain in Why #NoStalking is a good deal for publishers,
Individuals issuing the offer get guilt-free use of the goods they come to the publisher for, and the publisher gets to stay in business — and improve that business by running advertising that is actually valued by its recipients.
So, if you want to save journalism, the best of publishing and civil discourse that depends on both, bring back real advertising and cure the cancer of adtech.
The original version of this post was published in Medium on 23 January 2017. This is an experiment in publishing first in Medium and second here. We’ll see how it goes.
We didn’t have that in the old print and broadcast worlds, and still don’t, where they persist. (For example, on news stands, or when you hit SCAN on a car radio.)
But we have it in digital media.
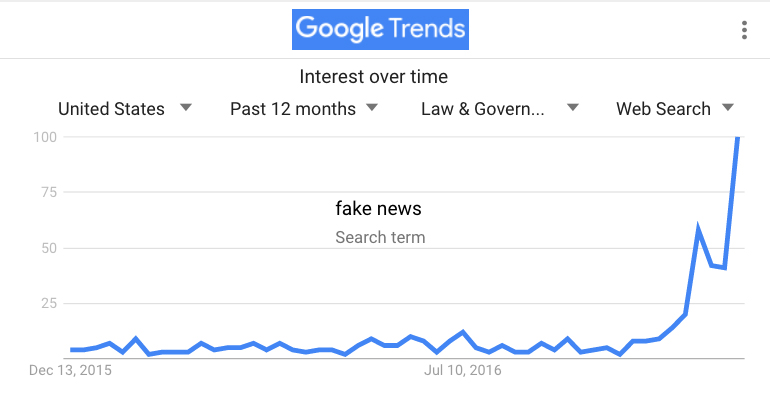
Here’s another difference: a lot of the stuff that gets shared is outright fake. There’s a lot of concern about that right now:
Why? Well, there’s a business in it. More eyeballs, more advertising, more money, for more eyeballs for more advertising. And so on.
Those ads are aimed by tracking beacons planted in your phones and browsers, feeding data about your interests, likes and dislikes to robot brains that work as hard as they can to know you and keep feeding you more stuff that stokes your prejudices. Fake or not, what you’ll see is stuff you are likely to share with others who do the same. This business that pays for this is called “adtech,” also known as “interest based” or “interactive” advertising. But those are euphemisms. Its science is all about stalking. They can plausibly deny it’s personal. But it is.
The “social” idea is “markets as conversations” (a personal nightmare for me, gotta say). The business idea is to drag as many eyeballs as possible across ads that are aimed by the same kinds of creepy systems. The latter funds the former.
Rather than unpack that, I’ll leave that up to the rest of ya’ll, with a few links:
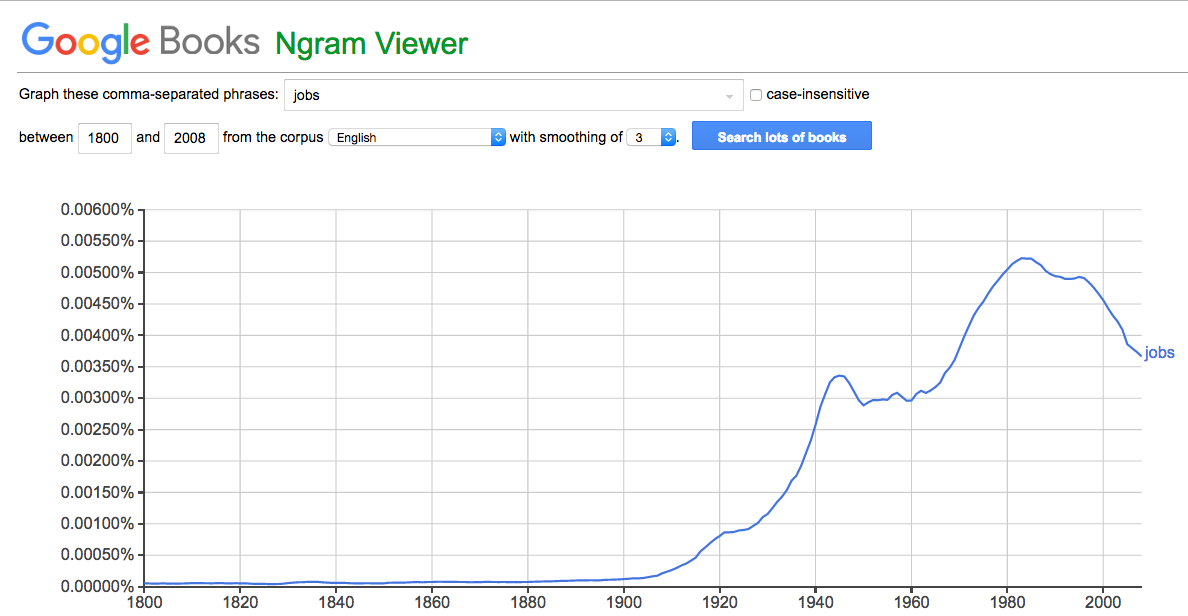
Like so much else the Times correctly tries to do, the piece issues a wake-up call. It is also typical of the Times’ tendency to look at every big social issue through the lenses of industrial age norms, giving us lots of stats and opinions from Serious Sources, and offering policy-based remedies (e.g. “help more middle- and low-income children acquire the skills that lead to good-paying jobs”).
It should help to remember that the ancestors who gave us surnames like Tanner, Smith, Farmer and Cooper didn’t have “jobs.” As a word, “jobs” acquired its current meaning after industry won the industrial revolution—and began to wane in usage after personal computing and the Internet showed up, giving us countless new ways to work on our own and with each other. You can see that in the rate at which the word “jobs” showed up in books:
I’m not even sure “work” was all the Tanners and Smiths of the world did. Maybe it was what we now call “a living,” in an almost literal sense.
Whatever it was, it involved technologies: tools they shaped, and which also shaped them. (Source.) Yet for all the ways those ancestors were confined and defined by the kind of work they did, they were also very ingenious in coping with and plying those same technologies. Anyone who has spent much time on a farm, or in any kind of hardscrabble existence, knows how inventive people can be with the few means they have to operate in the world.
This is one reason why I have trouble with all the predictions of, for example, robot and AI take-overs of most or all work. For all the degrees to which humans are defined and limited by the tools that make them, humans are also highly ingenious. They find new ways to make new work for themselves and others. This is why I’d like to see more thought given to how ingenuity shows up and plays out. And not just more hand-wringing over awful futures that seem to be linear progressions out of industrial age (or dawn-of-digital age) framings and norms.
Note: the spear point above is one I found in a tilled field north of Chapel Hill, NC. It is now at the Alamance County Historical Museum.
So I was on a panel at WebScience@10 in London (@WebScienceTrust, #WebSci10), where the first question asked was, “What are two aspects of ‘trust and the Web’ that you think are most relevant/important at the moment?” My answer went something like this::::
1) The Net is young, and the Web with it.
Both were born in their current forms on 30 April 1995, when the NSFnet backed off on its forbidding commercial traffic on its pipes. This opened the whole Net to absolutely everything, exactly when the graphical Web browser became fully useful.
Twenty-one years in the history of a world is nothing. We’re still just getting started here.
2) The Internet, like nature, did not come with privacy. And privacy is personal. We need to start there.
We arrived naked in this new world, and — like Adam and Eve — still don’t have clothing and shelter.
The browser should have been a private tool in the first place, but it wasn’t; and it won’t be, so long as we leave improving it mostly up to companies with more interest in violating our privacy than providing it.
Just 21 years into this new world, we still need our own clothing, shelter, vehicles and private spaces. Browsers included. We will only get privacy if our tools provide it as a simple fact.
We also need to be the first parties, rather than the second ones, in our social and business agreements. In other words, others need to accept our terms, rather than vice versa. As first parties, we are independent. As second parties, we are dependent. Simple as that. Without independence, without agency, without the ability to initiate, without the ability to obtain agreement on our own terms, it’s all just more of the same old industrial model.
In the physical world, our independence earns respect, and that’s what we give to others as a matter of course. Without that respect, we don’t have civilization. This is why the Web we have today is still largely uncivilized.
We can only civilize the Net and the Web by inventing digital clothing and doors for people, and by providing standard agreements private individuals can assert in their dealings with others.
Inventing yet another wannabe unicorn to provide “privacy as a service” won’t do it. Nor will regulating the likes of Facebook and Google, or expecting them to become interested in building protections, when their businesses depend on the absence of those protections.
Fortunately, work has begun on personal privacy tools, and agreements we can each assert. And we can talk about those.
This is a second draft of this post, corrected by Denise Howell’s comment below. Key facts: I am not a lawyer. She is. Good one, too. So take heed (as I just did). And read on.
Uber may, in Uber’s sole discretion, permit you from time to time to submit, upload, publish or otherwise make available to Uber through the Services textual, audio, and/or visual content and information, including commentary and feedback related to the Services, initiation of support requests, and submission of entries for competitions and promotions (“User Content”). Any User Content provided by you remains your property. However, by providing User Content to Uber, you grant Uber a worldwide, perpetual, irrevocable, transferable, royalty-free license, with the right to sublicense, to use, copy, modify, create derivative works of, distribute, publicly display, publicly perform, and otherwise exploit in any manner such User Content in all formats and distribution channels now known or hereafter devised (including in connection with the Services and Uber’s business and on third-party sites and services), without further notice to or consent from you, and without the requirement of payment to you or any other person or entity.
The emphasis is mine. Interesting legal hack there: you own your data, but you license it to them, on terms that grant you nothing and grant them everything.
Talk about a deal breaker. Wow. (Except it’s also the old deal.)
The new one goes into effect on 21 November. As I read that (when I wrote the first draft of this post), they have sale on personal data pending until that time.
At the very least, Lyft should make hay on this, if they actually do have an advantage in the degree to which they protect privacy. (Denise, below, says they don’t. But hey, maybe they could if they wanted to compete on privacy.)
Here’s what matters (and remains unchanged from Denise’s corrections):::
We need our own terms. Meaning each of us should be the first party in agreements with service providers, not the second. Meaning they need to agree to our terms.
That’s Customer Commons’ reason for being. Just as Creative Commons is where you will find copyright terms you can assert as an artist, Customer Commons will be where you will find service terms you can assert as a customer.
With the wind of new .eu and .au privacy laws (e.g. the EU’s GDPR) at our backs, we stand a good chance of making this happen.
The question is how we can get some mojo behind it. Thoughts welcome. Shoulders to the wheel as well.
Through the soundtrack of my life, nobody else taught more about how to be a man, a lover, and a human being with one foot in the temporary world and the other in eternity.
A couple weeks ago, I was driving to the Peets on Upper State Street in Santa Barbara when some station on the radio played the title song of Leonard’s new album, You Want It Darker.
I didn’t make it all the way. Had to pull over. There was no way I could listen and keep driving. It was too deep, too right. I had never heard it before, and it demanded full attention. Still does. The lyric begins,
If you are the dealer, I’m out of the game
If you are the healer, it means I’m broken and lame
If thine is the glory then mine must be the shame
You want it darker
We kill the flame
Magnified, sanctified, be thy holy name
Vilified, crucified, in the human frame
A million candles burning for the help that never came
You want it darker
Hineni, hineni
I’m ready, my lord
And he was.
I heard today, somewhere in the links below, that he recorded that final album in his Los Angeles apartment, on what turned out to be his death bed.
Nearly all the ads I see on Facebook are fake news items like these two, next to Mark Zuckerberg’s latest post, which is, ironically, about fake news:
Besides being false and misleading clickbait, these ads are not from espn.com. They’re from http://espn.com-magazines.online. They are also bait for a topic switch, since they’re actually about a diet supplement I won’t flatter by naming. So they’re two kinds of fraud at once: outright lies from a forged source.
It can’t be that hard for Facebook not to run this kind of obviously dishonest and misleading advertising, especially since this story itself is old news. (See here.) Why hasn’t it been stopped?
I’m guessing the answer is a technical one: that Facebook’s advertising system is too easy a hack for dishonest advertisers to resist, and too hard to change.
Either that, or the money they make from ad fraud more than offsets the cost of egg on their CEO’s face.
Economically speaking, the American healthcare system is not built for patients, because patients aren’t the ones paying for it directly. Insurance companies are.
See, health care in the U.S. is mostly a B2B insurance business. It is only B2C when insurance doesn’t cover expenses to the patient. And even then, insurance still pays for it when patients don’t.
The history of the U.S. health care industry is one essentially of regulatory capture by the insurance industry, which today is a vast interlocked cabal of insurance companies and kieretsus of hardware, software and service providers.
And, because this system is mostly disconnected from the controlling effects of direct accountability to patients (which we might have had if the system had been B2C), costs and inefficiencies within the system have grown out of control. To say the least of it.
We tend to make this mistake whenever we conflate customers and consumers. We do this most commonly in businesses that offer B2C services paid for in a B2B way—as we have in the insurance business called healthcare. The split between the two is real, but treated as if it is not. Thus we have companies going on about how much they care about their consumers, users or patients, who they say have a “choice,” when in fact they have little or none.
Thus it is a mistake to assume that patients have any direct economic influence over what they get from health care providers whose primary customers are insurance companies. It really doesn’t matter is the care is provisioned through an “integrated clinical practice” (Mayo Clinic) “integrated managed care consortium” (e.g. Kaiser Permanente), “healthcare delivery system” (e.g. Cone Health), “managed healthcare group” (UnitedHealth, Anthem, Aetna), a “federation” of the same (Blue Cross Blue Shield) or a plain old “health insurance company” (Humana), the business is almost entirely upstream of the point where care is provided: inside the insurance business that gets paid to fund the whole mess.
The main exceptions in this system are Medicare and Medicaid, which are basically government-run insurance businesses.
Companies with internal splits between their customers and consumers tend to be blind to what its consumers actually want or need — or can bring to the market’s table on their own — because money comes from somewhere else. It’s conflationary shell game, making it easy to think and say the consumer is actually a customer, or like a customer, when they’re not, because all the economic action is taking place elsewhere.
I’ve seen this for decades in commercial broadcasting, and with publishers whose primary customers are advertisers rather than those who “consume” what is now called “content” (as if it were nothing more than container cargo), even if those consumers in some cases (such as with newspapers and magazines) are paying subscribers. The primary customers are still advertisers and their agents.
I’m seeing it today in the cabal of perpetrators and beneficiaries of the four dimensional shell game that online advertising has become. This is why its members, all B2B businesses, miss the clear signal “users,” “consumers” and “the audience” are sending with ad blocking and tracking protection.
The only way we can begin to fix the U.S. healthcare system is by making patients as powerful and engaging as they would be if they were full-fledged customers of the care they receive, rather than mere consumers of services. And this can only begin with better ways for each of us to take control of our own health care data (which is valuable to those services), and how it is used by services mostly paid for by others.
The best approach I have seen so far to this challenge is HIE of One, a project of two MDs, Adrian Gropper and Michael Chen. HIE stands for Health Information Exchange, which Adrian and Michael describe as “a patient-centered health record based on the FHIR and HEART interoperability standards.”
Here is the main reason I like its chances: it is based on open source code already in development. This means many developers can step in and help raise its barn, for all of us.
If you’re a developer, and you care about the health of your self, your friends and family, and the human species, I highly recommend stepping up and stepping in. I can’t think of any #VRM project with more leverage on the good of the world—as well as one country’s most essential yet fucked-up service economy.
So here’s a message from humanity to Google and all the other spy organizations in the surveillance economy: Tracking is no less an invasion of privacy in apps and browsers than it is in homes, cars, purses, pants and wallets.
That’s because our apps and browsers, like the devices on which we use them, are personal and private. Simple as that. (HT to @Apple for digging that fact.)
To help the online advertising business understand what ought to be obvious (but isn’t yet), let’s clear up some misconceptions:
Tracking people without their clear and conscious permission is wrong. (Meaning The Castle Doctrine should apply online no less than it does in the physical world.)
Claiming that advertising funds the “free” Internet is wrong. (The Net has been free for the duration. Had it been left up to the billing companies of the world, we never would have had it, and they never would have made their $trillions on it. More at New Clues.)
What’s right is civilization, which relies on manners. Advertisers, their agencies and publishers haven’t learned manners yet.
But they will.
At the very least, regulations will force companies harvesting personal data to obey those they harvest it from, with fines for not obeying. Toward that end, Europe’s General Data Protection Regulation already has compliance offices at large corporations shaking in their boots, for good reason: “a fine up to 20,000,000 EUR, or in the case of an undertaking, up to 4% of the total worldwide annual turnover of the preceding financial year, whichever is higher (Article 83, Paragraph 5 & 6).” Those come into force in 2018. Stay tuned.
Companies harvesting personal data also shouldn’t be surprised to find themselves re-classified as fiduciaries, no less responsible than accountants, brokers and doctors for confidentiality on behalf of the people they collect data from. (Thank you, professors Balkin and Zittrain, for that legal and rhetorical hack. Brilliant, and well done. Or begun.)
The only way to fully fix publishing, advertising and surveillance-corrupted business in general is to equip individuals with terms they can assert in dealing with others online — and to do it at scale. Meaning we need terms that work the same way across all the companies we deal with. That’s why Customer Commons and Kantara are working on exactly those terms. For starters. And these will be our terms — not separate and different ones that live at each company we deal with. Those aren’t working now, and never will work, because they can’t. And they can’t because when you have to deal with as many different terms as there are parties supplying them, the problem becomes unmanageable, and you get screwed. That’s why —
There’s a new sheriff on the Net, and it’s the individual. Who isn’t a “user,” by the way. Or a “consumer.” With new terms of our own, we’re the first party. The companies we deal with are second parties. Meaning that they are the users, and the consumers, of our legal “content.” And they’ll like it too, because we actually want to do good business with good companies, and are glad to make deals that work for both parties. Those include expressions of true loyalty, rather than the coerced kind we get from every “loyalty” card we carry in our purses and wallets.
When we are the first parties, we also get scale. Imagine changing your terms, your contact info, or your last name, for every company you deal with — and doing that in one move. That can only happen when you are the first party.
So here’s a call to action.
If you want to help blow up the surveillance economy by helping develop much better ways for demand and supply to deal with each other, show up next week at the Computer History Museum for VRM Day and the Internet Identity Workshop, where there are plenty of people already on the case.
Then follow the work that comes out of both — as if your life depends on it. Because it does.
And so does the economy that will grow atop true privacy online and the freedoms it supports. Both are a helluva lot more leveraged than the ill-gotten data gains harvested by the Lumascape doing unwelcome surveillance.
Bonus links:
All the great research Julia Angwin & Pro Publica have been doing on a problem that data harvesting companies have been causing and can’t fix alone, even with government help. That’s why we’re doing the work I just described.
Everything by Shoshana Zuboff. From her home page: “’I’ve dedicated this part of my life to understanding and conceptualizing the transition to an information civilization. Will we be the masters of information, or will we be its slaves? There’s a lot of work to be done, if we are to build bridges to the kind of future that we can call “home.” My new book on this subject, Master or Slave?The Fight for the Soul of Our Information Civilization, will be published by Public Affairs in the U.S. and Eichborn in Germany in 2017.” Can’t wait.
Don Marti’s good thinking and work with Aloodo and other fine hacks.
I just unsubscribed from Staples mailings, and got this:
WTF? Is the request traveling by boat somewhere? Does it need to be aged before it works?
We have computers now. We’re on the Internet. There is no reason why unsubscribing from anything should take longer than now.
Staples is not alone at this, by the way.. Many unsubscriptions are followed by promises to complete over some number of days. I don’t know why companies do that, but it smacks of marketing BS.
If you’re listening, Staples, give me a good reason. I am curious.
For what it’s worth, I unsubscribed because approximately all the mailings I get from Staples (and everybody else) are uninteresting to me. Un-cluttering my mailbox is far more valuable than getting bargains (e.g. “$220 off select laptops and desktops” and “UNBEATABLE Ink & Toner Prices”) I’ll never bother with.

 My given name is David. Family members still call me that. Or Dave. Everybody else calls me Doc. Since people often ask me where that nickname came from, and since apparently I haven’t answered it anywhere I can now find online*, here’s the story.
My given name is David. Family members still call me that. Or Dave. Everybody else calls me Doc. Since people often ask me where that nickname came from, and since apparently I haven’t answered it anywhere I can now find online*, here’s the story. By that I mean nobody is going to trap it in a silo. Apple tried, first with its podcasting feature in iTunes, and again with its Podcasts app. Others have tried as well. None of them have succeeded, or will ever succeed, for the same reason nobody has ever owned the human voice, or ever will. (Other, of course, than their own.)
By that I mean nobody is going to trap it in a silo. Apple tried, first with its podcasting feature in iTunes, and again with its Podcasts app. Others have tried as well. None of them have succeeded, or will ever succeed, for the same reason nobody has ever owned the human voice, or ever will. (Other, of course, than their own.)




 I’ve long thought that the most consequential thing I’ve ever done was write a newspaper editorial that helped stop development atop the highest wooded hilltop overlooking the New York metro. The hill is called High Mountain, and it is now home to the
I’ve long thought that the most consequential thing I’ve ever done was write a newspaper editorial that helped stop development atop the highest wooded hilltop overlooking the New York metro. The hill is called High Mountain, and it is now home to the 







 Imagine you’re on a busy city street where everybody who disagrees with you disappears.
Imagine you’re on a busy city street where everybody who disagrees with you disappears.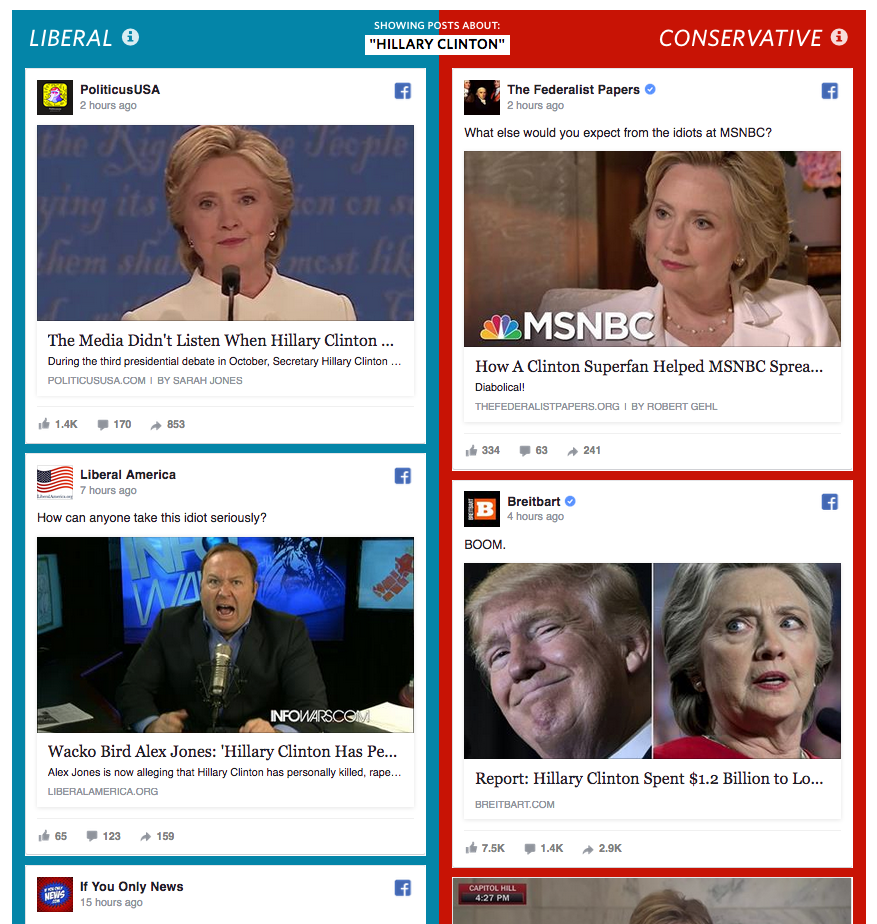


 I’m not even sure “work” was all the Tanners and Smiths of the world did. Maybe it was what we now call “a living,” in an almost literal sense.
I’m not even sure “work” was all the Tanners and Smiths of the world did. Maybe it was what we now call “a living,” in an almost literal sense.

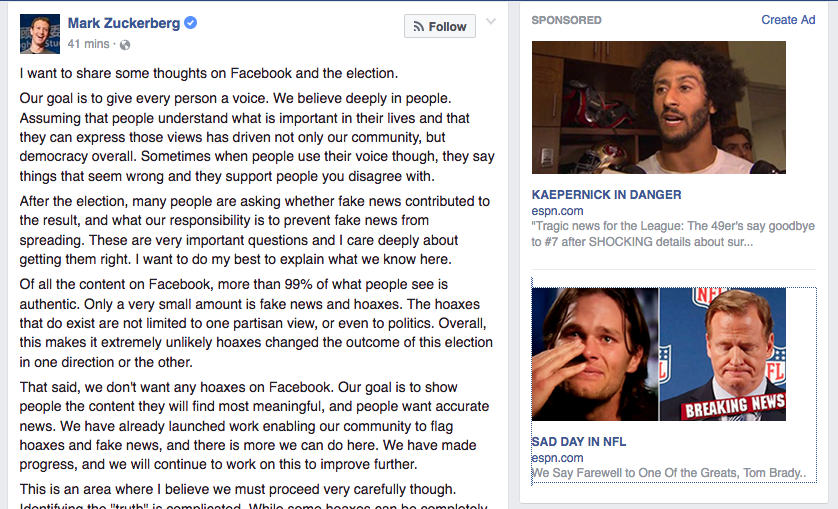 Besides being false and misleading clickbait, these ads are not from espn.com. They’re from http://espn.com-magazines.online. They are also bait for a topic switch, since they’re actually about a diet supplement I won’t flatter by naming. So they’re two kinds of fraud at once: outright lies from a forged source.
Besides being false and misleading clickbait, these ads are not from espn.com. They’re from http://espn.com-magazines.online. They are also bait for a topic switch, since they’re actually about a diet supplement I won’t flatter by naming. So they’re two kinds of fraud at once: outright lies from a forged source. Economically speaking, the American healthcare system is not built for patients, because patients aren’t the ones paying for it directly. Insurance companies are.
Economically speaking, the American healthcare system is not built for patients, because patients aren’t the ones paying for it directly. Insurance companies are.
{kind=link}