WBAG’s callsign stands for Burlington And Graham: two adjoining towns between Greensboro and Durham in North Carolina. I have many kinfolk in the hood, and have been living or visiting here all my life. As it happens, WBAG and I were also born the same year. So was the station’s broadcast tower, which stands in a field on Burlington’s north side:
Amazingly, WBAG is still using the same tower, manufactured by the Wincharger company, which continues to do what it did before and after its broadcast tower phase: make windmills. Here’s one of their ads from back when AM radio ruled the airwaves, and the company answered growing demand:
As it happens, I document broadcast towers and antennas (which on AM are the same), for two reasons. One is that I love broadcast engineering. The other is that I know many or most of these old towers will disappear in the next decade or two. For both reasons, I shot WBAG’s tower in 2015 and again a few days ago. It looked rusty as hell the first time, and it looks even more rusty now. Kind of like me.
But the station itself is quite the opposite. Live jocks host shows and spin records, there are nine local talk shows, and they have an abundance of local advertisers. While sitting here, I’ve heard ads for Franks Jewelry, Bulington Alamance Associate of Realtors, Little Donny Walker’s Car Wash, Sam’s Factory Outlet, Suretop Roofing, Always Best Care Senior Services, and Fisher Wealth Management (which also has its own talk show on the station). This things are rare in local radio today. Most stations have long since been bought out by giants (now bankrupt or headed there), and run canned content from elsewhere.
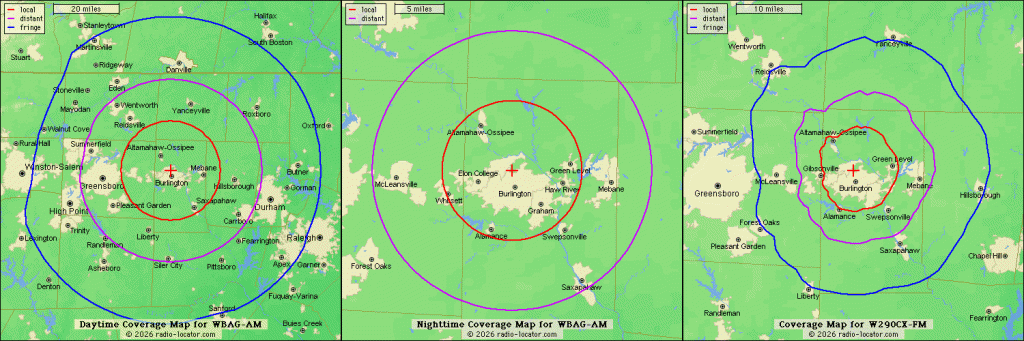
WBAG’s main format is oldies, with a focus on Carolina Beach Music. I grooved on this genre as a student at Guilford College from ’65 to ’69. Being of a geeky bent, I listened a lot to FM radio, which was still struggling then. My fave tunings were to jazz and blues from WAAA-FM on 107.5 from Winston Salem, and top 40 from WBAG-FM on 93.9. Both of those FM licenses were bought out when FM got hot. (WBAG’s 93.9 license now belongs to WNCB in Cary.) And while WAAA went through many call letter and facility changes (it’s now WTOB, the abandoned callsign of a former top 40 station in town), WBAG has remained itself continuously, eventually adding a small FM signal on 105.9 that covers Burlington, Graham, and Alamance County well enough. Here are its day/night AM and FM coverage areas:
Unlike most radio stations, WBAG doesn’t stream online. Instead, it lives in the natural world, where we still have distance, and the inverse square law applies, meaning the signals only go so far. That’s a charm of local radio.
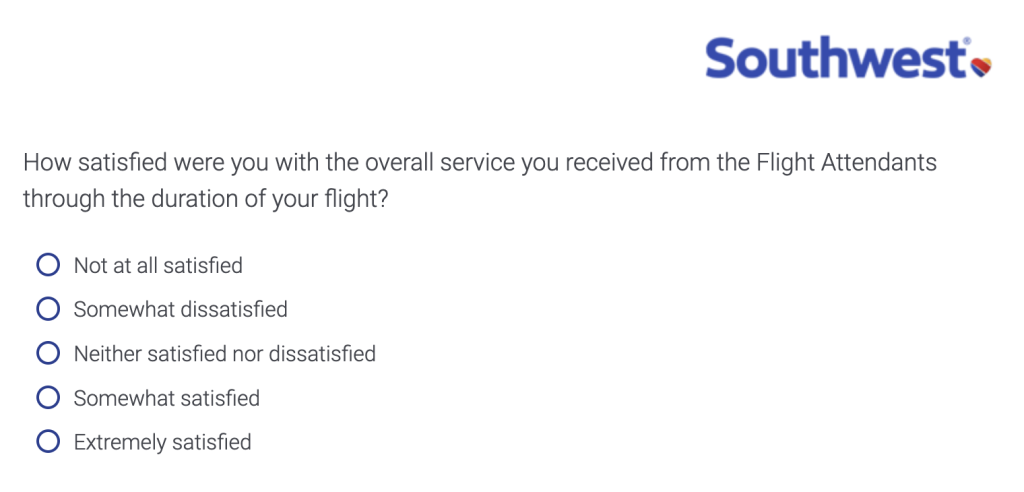
Here is what I wanted (and got) from Southwest: a clean window on a comfortable plane that i could find, board, and fly in easily. Most of that is not about flight attendants.
Here is the survey hook that came in an email after a Southwest flight:
And here is the first question in the survey one gets hooked into taking:
I gave up after it seemed that all the questions were about flight attendants. None were about the whole service experience. So one doesn’t have a way to report that the Southwest app sent me to a gate far out in one concourse—
Screenshot
—when it had been moved to another concourse:
I can say that one difference between United’s app and Southwest’s is that I have not yet had the same experience with United’s.
But both have the same long surveys for making me report on flight attendants.
Mozilla’s The State of Open Source AI is required reading. It makes a great case for open source (and open weight models). This is essential in the current political, economic, and development battles between those and the big closed US-based companies and models. We will see the earlier open source battles (geeks vs. IBM, then Microsoft, et. al.) play out again, only faster.
I also love what he says about the browser as an agent. Good stuff.
But the word personal doesn’t appear. Local appears twice. User appears seven times, all inside the section titled The agentic harness is another user agent. Again, great stuff in that section.
Still, it’s like we’re arguing about democracy in feudal Europe or Japan.
Haven’t figured out lighting yet, but I like the idea
After struggling for days to make my new Epson FF-680W photo scanner, which does a much poorer job of scanning photos than my iPhone 16, I’m ready for one of these.
On your Outage Information and Troubleshooting page, just @#$%^ tell us where your @#$%^ outages are. Don’t require an account holder’s zip code and phone number first. When you’re just a friend trying to help the account holder over the phone (still working over the cell system), that information isn’t always available. Or necessary. Out is out. You’re a @#$%^ utility. Your outage is public information—or ought to be. Thank you for your service. When it’s back.
OpenAI put the fire alarm on payroll, borrowed its medal for the pitch deck, and called the whole thing responsible AI…
BigMac did not create cheaper intelligence. It found the GPU waste inflating its price, and gave token economics a reason to fall by multiples…
Kimi did not reveal a Chinese threat. It revealed Silicon Valley has no shared answer for AI except that somebody else should pay more for it…
Gemini’s 950 million users do not prove Google built the best AI. They prove the best AI loses when it asks people to go somewhere else…
We’ve helped promote over 500 Tech Brands. Will yours be the next?
In May of 2018, I posted GDPR will pop the adtech bubble. It didn’t. The bubble is now bigger than ever. My mistake was assuming that there was a policy answer to a morally awful business that paid well. In retrospect, it’s a humbling reminder of how long one can be wrong about something—and that maintaining a wrong doesn’t make it right. That’s why we were already working on MyTerms (IEEE 7012) at the time. It’s done now, and ready to rock what’s overdue to pop.
And this subscription cancellation was made by a human being
In tech journalism’s golden age, when mags were thick and slick and hot, and covered world-changing work like a swarm of noisy bees, the most readable, annoying, hated, and loved writer of them all was John C. Dvorak, who died three days ago at just 80.
In Quaker meetings, the rule is not to speak until you can improve on the silence. In tech journalism, the rule is not to speak until you can improve on the cacophony of good things others are saying and writing, while not knowing if what you’re writing works or not, but you can’t stop doing it anyway. I learned a lot about all that from John. Hats off.
Coffman has described his overnight stays as a form of quality control, allowing him to evaluate whether Aurora’s incentive-based model is helping residents move toward stable housing. He plans to continue sleeping at the shelter every Friday until the program reaches its full potential. His goal is to create a model that other cities can follow.
Nitin Badjatia has been laying out more and more reasons—and ways—that enterprises will adapt to customers, rather than the reverse. More at ProjectVRM.
We need different words for human and machine intelligence.
The human kind is a quality, like empathy, anger, or contentment. You can’t measure it, as if with a ruler or a dipstick. If you could, you’d get the same measure every time. IQ testing pretends to measure intelligence, but it doesn’t. (I speak as a former schoolkid whose known IQ scores had an 80-point range—and was at different times rewarded for being smart and punished for being dumb. Fact: I was both all along. So are we all.)
The machine kind is a quantity. You can measure it in various ways, but economically the AI commodities for sale are called tokens. Kieth Teare visits this fact at length and depth in Intelligence: Who Owns it? Excerpt:
We should stop talking about AI as a feature and start talking about intelligence as the universal thing that is delivered as an input to the world.
Water is an input. Electricity is an input. Literacy is an input. Connectivity is an input. Once a society depends on them, access stops being optional. Nobody needs government to build every well, power plant, school, or network. But everybody understands that a civilization cannot be organized around less than universal and reliable access to foundational inputs.
Intelligence is reaching that level of importance now that we all know it is real.
Government should not own it, operate it, or develop it. Quite the opposite. Companies are the right actors to build fast, compete hard, improve models, serve customers, and discover the real use cases. Self-interest is a useful framing here. Markets are good at finding demand, reducing costs, and turning invention into services people actually use.
Companies are the right operators, developers, and owners. But that does not settle the real question of who owns the benefits. That is an economic question.
If intelligence becomes metered infrastructure, what happens to the value it creates?
He concludes,
My view is this:
The central product of this era is intelligence. Companies have figured out how to capture it, package it, serve it, and meter it. That is good. It should stay in the hands of builders who have the incentive to make it better.
But intelligence is too foundational to become just another private toll booth. A significant part of it will turn out to be free to users.
As intelligence becomes a general-purpose resource, then access to it becomes a human-capability question, and the surplus from it becomes an economic-justice question. Not because government should run it. Because government should not run it. The operating layer belongs with companies. The wealth question belongs with everyone. But companies are best placed to turn that into a process of distribution.
The question is not whether companies should build intelligence. They should.
The question is whether humanity gets a stake in the wealth created by the thing that may soon become its most important shared input.
An important read, even if you disagree with some of it. My main issue is differentiating between the human and machine forms of intelligence. We’ve always had a word for the former. We need a new word for the latter.
This is the first morning since I arrived in Baltimore on Wednesday that stepping outside in the morning didn’t feel like walking into an oven. It was 76° F (24.4° C), which isn’t bad. I also couldn’t see far up the road, because the air was full of smoke, and it was hard to breathe. See the above.
My question is whether we should even get in the car to go somewhere. Wired has advice.
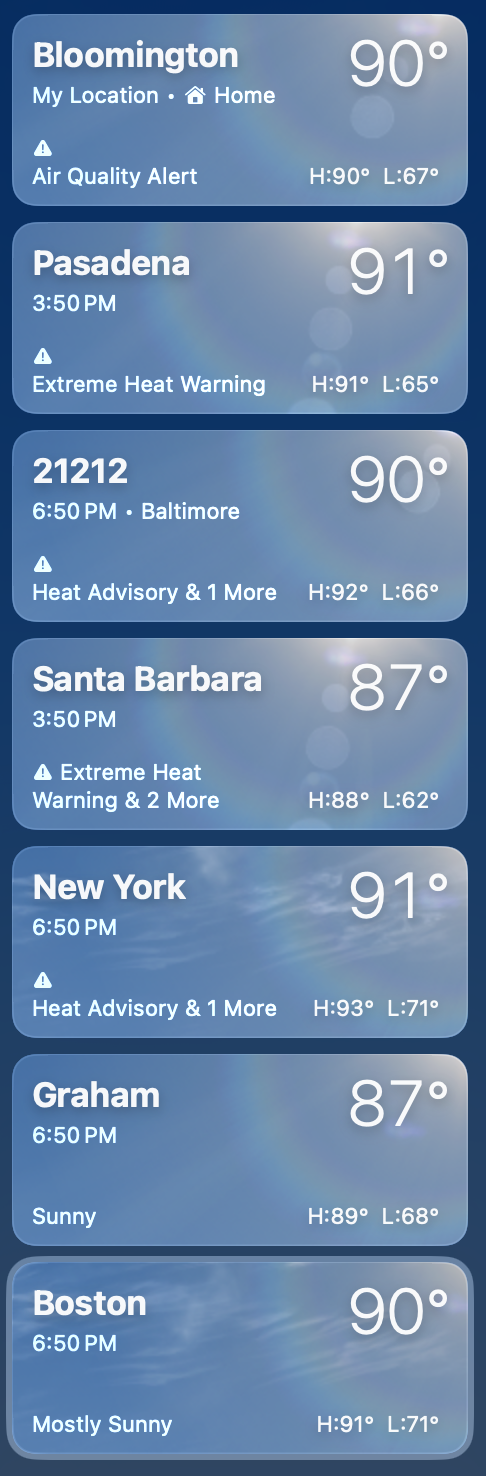
That’s all I have to prep for a month on the road. Tomorrow is Baltimore. After that, North Carolina. After that, California. Back in Bloomington in mid-August. Right now it’s hot in all my places:
All within 5° of each other.
Ground down
Says here that Rogers Sports & Media has closed six of its radio stations. One of those, CKWX /1130 in Vancouver, I enjoyed listening to in Hawaii. One was an FM, too.
Mesa Mike’s List of Deleted AM Radio Station Facilities is huge, but limited to stations that are now defunct. Many more are still licensed but silent (e.g. 560 AM in San Francisco), operating from highly diminished facilities (e.g. WDNC/620 in Durham, WMEX/1510 in Boston), or slowly shrinking away (WSCR/670 and WBBM/780 in Chicago, WCCO/830 in Minneapolis).
Alas, NiemanLab (which I have long followed, honored, and even loved) joins TechCrunch in lauding a new app called HyperTexting for not calling what it relies on “RSS“:
Hailey isn’t the only one attempting to introduce the technology formerly known as RSS to a younger generation. (Nieman Lab predictors have been saying this was coming for a few years now.) The Electronic Frontier Foundation published a guide last month to “a tool that’s been around for decades that can help wrangle many of your feeds into something manageable.”*
RSS stands for exactly what it is: Really Simple Syndication. Changing RSS’s name now is like saying “online publishing, formerly known as the Web.”
The perp here is Caleb Hailey, who wrote The social-media-like interface to explain why he wants to re-brand RSS with his own app. He (and NiemanLab, it seems) blames RSS readers for what he sees as a stink on the standard. In making what he claims is a better RSS reader, he explains,
In order for RSS to succeed reach escape velocity, I think we need to stop saying “RSS”.2 That’s why, if you look closely, you’ll see that I’ve gone out of my way to avoid using terms like “RSS”, “Atom”, “JSON Feed” or “OPML” in the HyperTexting app and website.
That’s a dis on the work Dave Winer and other developers have put into making RSS, OPML, and other standards sturdy, useful, and generative. For example, here:
You Can Now Chat Using RSS
*By Jon Henshaw* in Social Media News Jul 13, 2026 (Last updated on Jul 13, 2026)
Dave Winer, creator of RSS 2.0, built RSS Chat using open web standards to create a simple way to chat and follow conversations. Dave Winer, the person who made Really Simple Syndication (RSS 2.0) the standard for following blogs in feed readers, asked whether RSS could be used for online chat, and quickly concluded that it could.
Using a combination of open web standards, RSS 2.0, OPML, Markdown, SQL, and WebSocket, Winer created RSS Chat. Winer said the part that makes it RSS-based is that every user has an RSS feed with all their posts, the whole community has an RSS feed, [and] there is an OPML file that list all the users.
That’s on top of nearly all of Web publishing, and podcasting. Heard of those?
Hell, RSS isn’t a drag on the apps that use it. It’s the sea that floats all their boats.
*All three of the links in that paragraph are pro-RSS. None say a renaming is “coming.”
2. [Caleb’s footnote says, “Hi Dave. 👋 I see you and I’m a huge fan! I suspect you may have thoughts™ on this take, but I think it’s possible we might agree more than we disagree. ↩︎” ] Sorry, Caleb. It’s still a dis. Call your product what you like, but don’t shit on the standard which, more than any other, makes your product possible.
Just a theory
LeBron is going to Miami. Old connections. Fun team with Giannis and Bam there. Lots of great golf, year-round.
I’m still an optimist
Rose Horowitch in The Atlantic: The End of Reading Is Here. Subhead: “Optimists once believed that universal literacy was inevitable. Now it seems that the age of reading might be a short anomaly in human history.” It’s an excellent piece. Worth the subscription.
On the day I shall have an item delivered from our One true online retailer and weekday sponsor.
To whom else has God sold naming rights for days of the week?
And you thought Tuesday was a grace of our turning Earth.
<bonus content to avoid if oral surgery grosses you out>
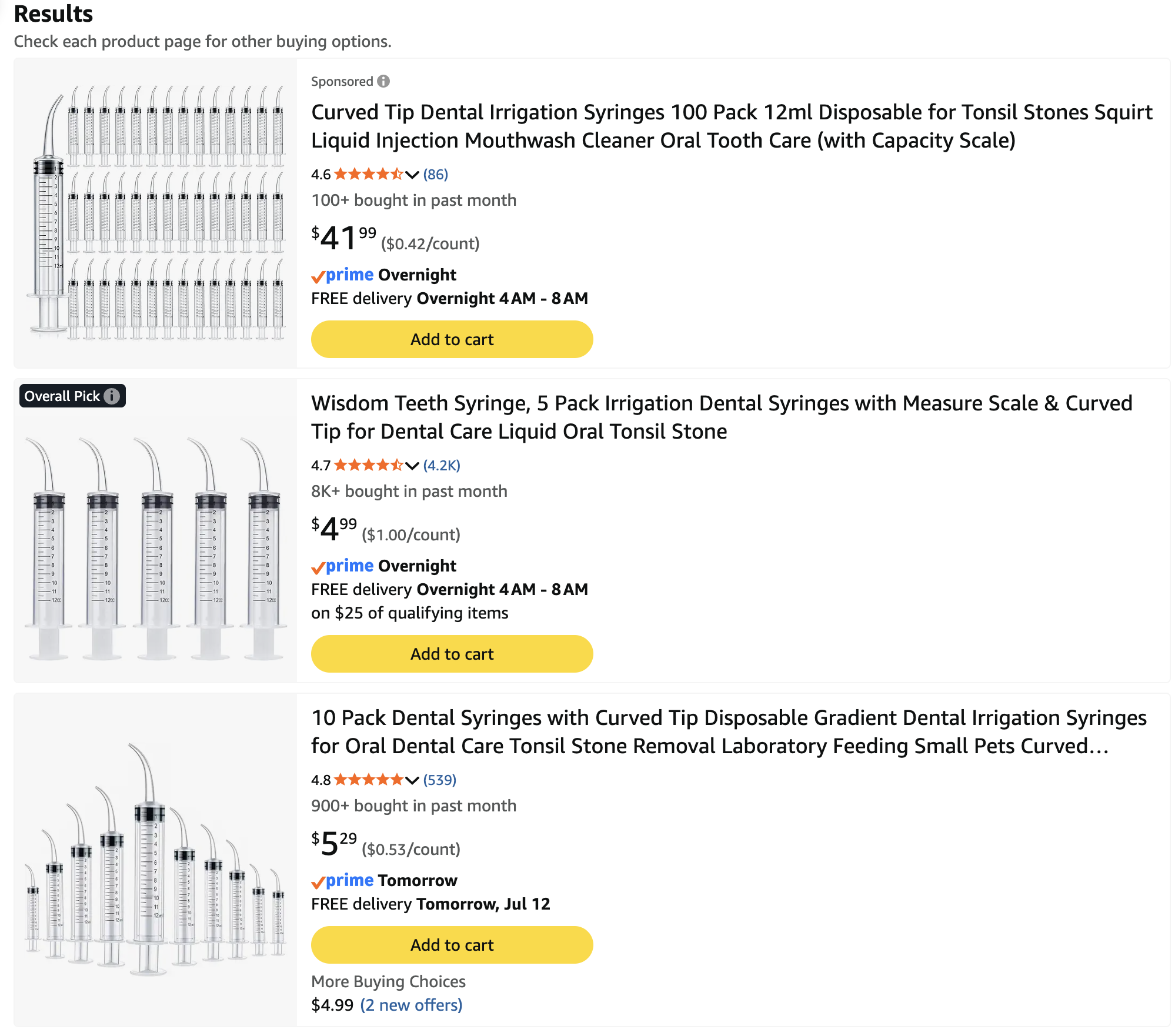
Since I had a molar extracted last week, there remains an open wound in my mouth where the tooth used to be, and in which food might lodge. This requires a liquid-ish diet of food without things in it. (Worst possible kind of thing: popcorn.) It also requires instrumentation for washing out the wound gently. This took me to a Walgreens in downtown Minneapolis, where a pharmacist told me I needed something that my surgeon never brought up: curved-tip dental irrigation syringes. Which Walgreens does not have, but Amazon offers in plentitude:
The list goes on, verily: longer even than a CVS receipt.
The best part is the reviews. Examples:
helps in feeding baby birds that fell out the nest and r scared and won’t eat
So long as you arent using them for epoxy they work fine
I got these because I have to measure out precise amounts of tint to add to a topcoat I’m using to finish off some cabinetry. It’s very small amounts, so using a measuring cup or even measuring spoon wouldn’t yield consistent results. So, these syringes should do the trick nicely.
Perfect for feeding found baby birds as they grow. You will need to snip off the tips to make wider aperatures as the birds get big.
Looking forward to my first dove chick and/or cabinetry job.
</bonus content to avoid if oral surgery grosses you out>
Downtown Minneapolis, which I shot on approach after posting this.
I leave shortly for fun family matters in Minneapolis. Meanwhiles, here are some worthy tabs to close:
While finding this kindness by Kaliya Young (quoting a now-vanished utterance by the late and very great Craig Burton) published in 2005 on her IdentityWoman blog, I also dug her latest post there, which is about commons and how they work, nicely comparing Cory Doctorow’s enshittification descriptions with old-fashioned (but more current than ever) enclosure of commons, closing off wide open public digital spaces such as the Internet, the Web, email, and other graces. She offers open protocols as one solution, which brings us to—
Vint Cerf is retiring from Google, which he has long served by continuing to work for everyone, and the Net he helped invent, rather than just for his employer. Among other things you’ll find at that last link is this: “…he predicted that formalized protocols would emerge as a foundation for the next generation of AI systems, echoing the role standardized internet protocols played in the web’s early expansion.”
I have used Garmin BaseCamp for many years to extract tracks and use its map for many purposes, such as to identify what it was I’ve seen and photographed out the windows of airplanes. But, as it says at that Garmin link, BaseCamp is for very old-fashioned Intel-based Macs, and for newer ones running Rosetta, which Apple is abandoning. I have thousands of tracks I want to keep and visualize on a map, using software that can download and store those tracks somehow. BaseCamp did that. Google Earth chokes on that many tracks. GPXSee is just a viewer. QMapShack is geekware at this stage. MyTracks might do it, but it choked on my first attempt just to download my latest tracks off my Garmin eTrex 22X GPS. (It does well with tracks off its own app on my iPhone.) Anyway, I welcome recommendations.
CKM Syndrome is a big deal. Read about it. Better than even chance you may already have it. You’ve been warned.
MySignals may be one of those enclosure-preventing protocols talked about in #1, above.
A couple of weeks ago, in The George Carlin Model of AI, I said personal AI needed to work first on what George called a place for my stuff.
Should Apple occupy that whole personal space, kinda like René Magritte visualized in a surrealist painting seventy-five years ago?
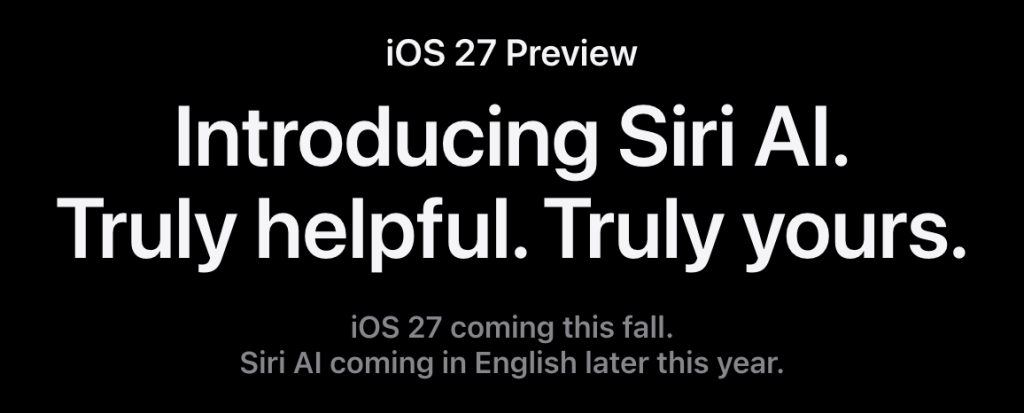
I think that’s where they’re going. You can see hints of it in the headline (as of now) at apple.com/os/ios/:
Siri is Apple’s Clippy. Maybe worse, because it’s still alive and unloved after fifteen years of relentless promotion and disappointment. (Start reading down from the Reception subhead on Siri’s Wikipedia page for a partial account of Siri’s failings. A lot there.) But Apple is investing the next generation of Siri—Siri AI— with huge new responsibilities—to you. But is it really—
?
On the privacy topic, Apple smokes a lot of its own exhaust. Find examples here, here, here, here, and here. A couple of years back, in response to the first of those, I wrote here and here about how Apple falters on the privacy front, despite its many promises. But I give it points for staying on the case, which will get a lot bigger with its next operating system.
Coming to a pocket near you… The Siri AI glowup hits the small screen. See Siri AI in the role of a lifetime: your personal assistant.
Ask Siri anything and revisit your conversations with ease in a new dedicated app.
Watch Siri embark on a quest to provide nutritional details about your meal. Yummy.
Cheer as Siri AI handles every detail of your soccer watch party. Go! Siri is giving main character energy and puts the personal in personal assistant.
See next-generation Apple intelligence extend, reframe, and clean up your photos. Booya!
Create photorealistic images and flex your imagination everywhere from contact posters to fun wallpapers in the all-new Image Playground.
Safari has never been more organized with topics, or timely with Notify Me. Rest easy knowing your data is protected as compromised passwords are automatically updated with just a tap.
And see Apple intelligence stand guard to protect your privacy. A faithful Sentinel keeping your private info private. With Siri and Apple intelligence, your data stays protected.
All this and so much more coming to an iPhone near you.
I think it needs to be a box: a dedicated one, like your closet or garage. I also think it’s coming, because Apple knows why Mac Minis are selling out:
I think this suggests that Apple will pitch the next Mac Mini (an M5 one) as the personal AI machine, meaning the place for your stuff.
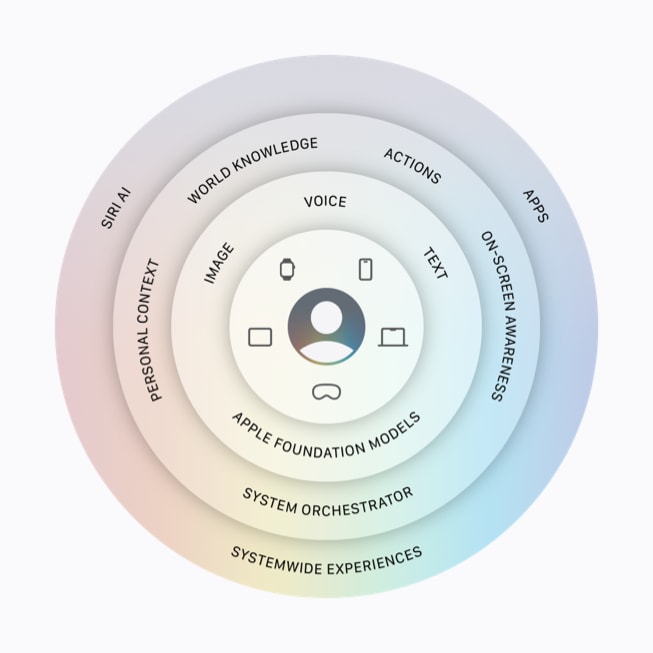
Now let’s look at some of the specifics behind the promotional jive:
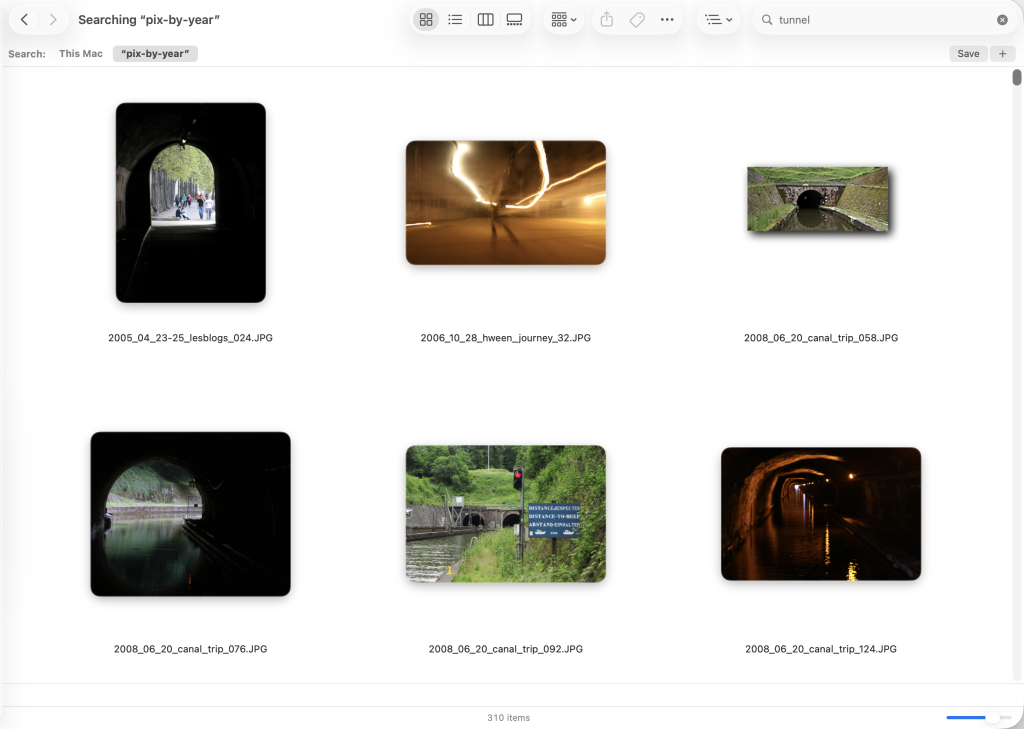
1. On-Device “Personal Context”: A new architecture (not the old Siri) maps your device locally, using Apple Silicon’s Neural Engine to index information across your Apple applications: contacts, calendar, reminders, messages, emails, documents, photos. As for your non-Apple stuff, such as my million-plus photos (a small sample) that are not in Apple’s Photos app, it looks like it’s already on the case. When I search for “tunnel” across my photo directories with my laptop (2023 MacBook Pro running Tahoe 26.5.1), I get every shot where that word appears, plus lots of stuff that is either a tunnel or looks kind of like one. Example:
Clearly an AI does some pattern recognition there, but is that “personal context”? I dunno.
It does have “Semantic Indexing,” which makes informed presumptions about the meaning of your data, and not just your keywords. Big AI does this now, but Siri will do it just for you, on your stuff, inside your place for it. Note what it says under the “Apple Intelligence in Apps” subhead here:
Express yourself through photos and images, save time with Safari, and get more done with Apple Intelligence seamlessly integrated into your everyday apps and experiences.
But do we want “seamless” everything? We need edges and boundaries to make sense of the world. In the absence of those, I want to turn that off, not turn it on, or to educate my personal AI about what’s what, and where it belongs.
2. Private Cloud Compute (PCC) is how Apple describes another place for your stuff: kind of a private office in Apple’s high-rise downtown. Specifics:
For advanced features that need to reason over complex data with larger foundation models, we created Private Cloud Compute (PCC), a groundbreaking cloud intelligence system designed specifically for private AI processing. For the first time ever, Private Cloud Compute extends the industry-leading security and privacy of Apple devices into the cloud, making sure that personal user data sent to PCC isn’t accessible to anyone other than the user — not even to Apple. Built with custom Apple silicon and a hardened operating system designed for privacy, we believe PCC is the most advanced security architecture ever deployed for cloud AI compute at scale.
The authors of that text are Apple Security Engineering and Architecture (SEAR), User Privacy, Core Operating Systems (Core OS), Services Engineering (ASE), and Machine Learning and AI (AIML)—all inside the company. They say lots more at that last link, all helpful to know. So is Expanding Private Cloud Compute, by the same teams.
3. Systemwide app actions: This new assistant can, for example, cross-reference a tracking number from your email and a message thread to find who asked for it, pull out other relevant information, then automatically drop it into a reply for you to review or edit before you send it, all in your virtual cabin (device) or office (private cloud).
4. Controlled federation, anonymized gateways, a privacy shroud, and other jive required to make this work:
I gather, from Apple’s literature, that Siri strips out your IP address and personal identifiers before making a query to an external AI. The external AI agent sees only the isolated query. This prevents the external AI from examining the personal stuff in your online home.
Now here is a tough question: What if only a giant can put together most or all of what we need? Three giants currently furnish most of our personal spaces in the digital world:
Apple (iOS and MacOS devices, Safari browser, etc.)
Google (Android devices, Gemini, Chrome browser, etc.)
Microsoft (Windows OS and devices, apps, etc.)
With iOS and MacOS 27, Apple moves to the front of that pack in the personal AI space, and will likely be the only giant to offer something that looks like a place for your stuff. Given its role in the surveillance fecosystem, Google can’t be trusted. Microsoft still has Micro in its name, so the positioning is good, but it has become much more of an enterprise company in recent years. So, among giants, Apple is it.
Now let’s talk about agents.
Apple sees you with just one: Siri AI. But you will probably need many agents: one or more for health (in various specialties), financial (banking, investment, credit), travel (airlines, car rental, hotels), home economics (property, stuff in storage, scheduling the kids, keeping the car working), legal (all your contractual commitments, plus much better customer-company interactions than are possible today).
Here’s the thing: if a single chatbot request is too risky to run unverified, what does that say about agents?
A chatbot is one request in, one answer out. An agent runs that risk in a loop: reading email, opening files, calling tools, handing work to other systems, unattended and at machine speed.
No breach required. An agent doing exactly the job you gave it moves your data constantly into places you don’t control and mostly can’t see.
Now wire thousands of agents together, the way every enterprise is planning to this year. Whatever the per-step risk is, compounding turns it into a certainty.
Apple just deployed Confidential AI to protect the smallest risk surface in AI. Enterprises are wiring up the largest with nothing underneath it.
Opaque sells arms to enterprises, so it’s not in the personal AI business. But it does make a good point in its opening sentence:
“Apple looked at a simple chatbot, the single most contained form of GenAI there is, and decided the data it leaks is too dangerous to ship to their customers without Confidential AI underneath it.”
To Apple, the more personal the context, the higher the privacy stakes. That’s why it believes personal AI has to run—
on-device (the place for your stuff) and
in a privacy-walled cloud infrastructure (your private office in Apple’s high-rise cloud)
The former can actually cover a lot of ground in your life, just by helping you get on top of all the stuff in your digital home. It can also handle some simple interactions with outside entities, such as MyTerms ceremonies and record-keeping.
But you’ll need much more from your personal AI if you’re going to scale your life out into the larger world, where nearly every company, every government agency, everything you might subscribe to, and even every church and nonprofit, wants to have AI agents for interacting with you and your digital agents.
Apple Intelligence is a generative AI (GenAI) service provided by Apple on its devices. While offering a similar set of features as other similar GenAI services, Apple Intelligence is claimed to be designed with an extra focus on user security and privacy through a two-stage authentication and authorization design using anonymous access tokens. In this paper, we present our investigation into this token issuance mechanism with a goal to reveal possible vulnerabilities using traffic analysis, reverse engineering, and cross comparison with Apple’s public documentation. Specifically, we present the Serpent attack, the first practical cross-device token replay attack against Apple Intelligence that allows the attacker to steal the access tokens from the victim’s device and utilise them on a different device, with all usage rate-limited against the victim. We have achieved successful attacks on the latest macOS 26 Tahoe and demonstrated that an attacker, who even has used up its own allowance, can immediately regain access to Apple Intelligence service. We have responsibly disclosed the vulnerabilities to the vendors and received confirmation from Apple with CVE assigned and bounty given. Our results highlight a general lesson for built-in AI services: Anonymising identity does not by itself make the AI service secure; Enforcing non-transferability requires cryptographic binding to the rightful user.
We assume that macOS 27 and iOS 27 will address those concerns, plus a near-countless number of others. We’ll know later this year, presumably. (Apple is better with promises and forecasts than most other giants, but not perfect.)
Humans invented privacy with the technologies we call clothing and shelter. We don’t have clothing yet in the digital world, or we wouldn’t be walking worse-than-naked across the Net, covered with thousands of invisible data-sucking ticks called cookies and tracking beacons: parasites that report who-knows-what to god-knows-who, across thousands of unseen and unknown paths.
But we might get shelter, or the beginning of a working model for it—a place for our stuff—from Apple and these other companies and projects.
Apple seems to understand some of this, at least architecturally, to some degree. I think others (including those listed here) understand it more deeply. But none of them have Apple’s heft.
For an enterprise view of this, read Nitin Badjatia, Iain Henderson, and Jamie Smith. All three see empowered customers coming to the marketplace with agentic AI capabilities that will strip the gears of existing enterprise systems, including those with AI agents.
Apple just set the bar every enterprise will be measured against
Escape velocity is the moment a category stops needing evangelism, when the question flips from “do I really need this?” to “why don’t you have it?” Three things flipped it this month.
First, the existence proof landed at the hardest difficulty setting. Apple just rolled out the largest Confidential AI deployment in history: every iPhone, at consumer latency, consumer cost, consumer scale. Every objection enterprises have leaned on, too slow, too expensive, more than we need, just got falsified a billion times over by a phone.
Second, this is already how the giants operate. Meta runs WhatsApp message AI through private processing. Google built Private AI Compute so Gemini can process your personal data in a sealed environment that, in Google’s own words, not even Google can access. Anthropic and TikTok run their own implementations. And Microsoft, Google, and NVIDIA ship the underlying confidential infrastructure across their clouds and silicon. The pattern is consistent: every company with world-class security talent, when forced to put AI against sensitive data at scale, lands on the same architecture. When that many teams solve the same problem independently and arrive at one answer, you’re looking at convergence.
On our side—the customer’s side—we need confidential personhood, based on personal sovereignty: root for the person. In other words, personal AI needs to be operated by the person, not just for the person.
So let’s suppose Opaque succeeds perfectly. Enterprises will have attestable hardware, secure enclaves, confidential containers, encrypted memory, verifiable runtimes, machine-speed agents, and other whatevers we’ve been reading about.
We will need the same. The flow should go like this:
Natural person
↓
Personal AI
↓
Personal terms (MyTerms)
↓
Confidential runtime
↓
Outside agents and services
↓
Network
Note also that the flow here is top-down from the person, the individual—rather than bottom-up from “the consumer” or “the user.”
Almost everybody talking about agentic AI today is looking only at the lower half. But that half won’t run without our permissions from the upper half. That’s why we (I was the chair) worked for nine years on IEEE 7012-2025—Standard for Machine-Readable Personal Privacy Terms, nicknamed MyTerms. As I say at that link, MyTerms is the only way we’ll get personal privacy in the digital world. Apple, please adopt it. Everyone else, jump on board too. It’s radically simple to implement:
MyTerms are contractual agreements about personal privacy that you proffer as the first party, and the company agrees to as the second party. With MyTerms, you don’t “consent” to the company’s privacy policies or whatever they say about their use of cookies. They agree to your privacy requirements, which will limit the use of cookies and tracking tech to only what you allow. You are not a mere “user” or “client.” You are an independent human being operating with full agency.
In a way, Aaron Fulkerson’s post argues a need for work on the upper half. Because, while he says, “the request never travels on trust,” our social and economic lives are based entirely on trust: contracts, promises, agreements, agency, representation, delegation.
If my personal agent books a hotel, negotiates a subscription, grants limited use of my health data, tells my bank to move money, buys something, or participates in market intelligence that flows both ways, those acts and processes aren’t just computations and transactions. They are relationships. And those require identity, delegated authority, obligations, records, audit trails, and remedies. Those all need to start with My Terms.
At scale, remedies also need to be based on ODR (online dispute resolution), which is thankfully a mature field—and one that MyTerms will expand.
I suspect Apple, Opaque, and MyTerms are each solving a different problem posed by a place for my stuff:
Layer
Question
Example
Confidential computing
Can I trust the machine?
Opaque, et al.
Personal context
Does the machine know me?
Apple, et al.
Personal sovereignty (confidential personhood)
Does the machine represent me?
MyTerms
Dispute & accountability
What happens when things go wrong?
ODR
In each case, the place for my stuff is a machine: my (or your) machine, and possibly my (or your) private cloud. Nobody is building that whole stack yet. Nor should anybody. Not if we want each layer to scale.
So here is a question. What if:
Apple provides the shelter (then competitors follow),
Opaque (and its competitors) provide the locks,
Linux and open source hacks provide the plumbing, and
MyTerms provides the constitution—or at least some solid ground under a new constitution for personal agency, independence, and privacy online?
…what I see based on what I saw yesterday is a world where Apple takes the AI consumer lead in relatively short order. Millions of people next year walking around talking to Siri AI, asking her all sorts of things and tasking her with all sorts of things. It’s a mixture of the power of the default, Apple’s own superior product instincts…
Whether Apple wins that battle or not, personal AI will become ubiquitous, and personal agents will do things that matter legally and socially. The big questions then will be, “Under whose authority?” and “How is that authority secured?”
The answers to both require contracts in which the person is the first party. Fortunately, contract law is well established everywhere, and contract itself is specified by Article 6 of the GDPR as one of the lawful bases for processing personal data. (Dive deeper here if you like.)
So, while we wait for Apple to drop other giant shoes, let’s start putting MyTerms to use. Our home—places for our stuff—on the Net won’t be secure without them.
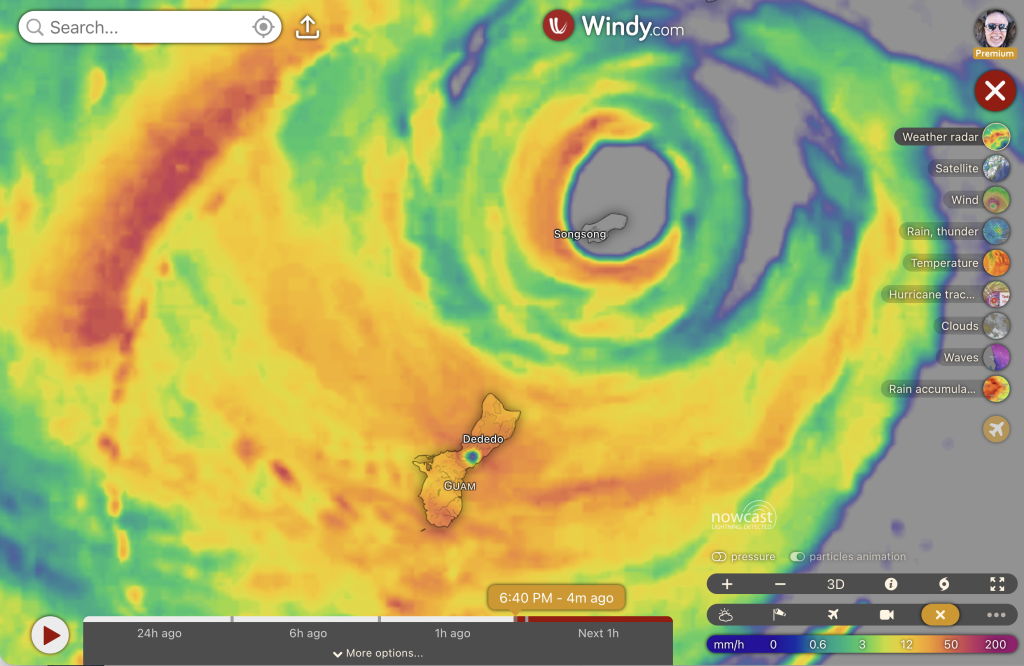
Super Typhoon Bavi, at 8:44 am local time, with the eye over Rota and the town of Songsong. Via Windy.com
Super Typhoon Bavi, not to be confused with Typhoon Bavi of 2020, is spinning into the Northern Marianas Islands, including Guam. NPR: “The super typhoon was moving north with maximum sustained winds of 165 miles per hour on Sunday, according to Guam’s Joint Information Center. The Joint Typhoon Warning Center (JTWC) estimates that Bavi’s winds could strengthen to 180 miles per hour as it passes over the islands, which is a major category five storm.”
Songsong, inside the eye right now (8:44 AM local time), is a village on the island of Rota. Its population in 2000 was 593.
More possible sources for information about the typhoon:
Back in 2005, Earl Monroesaid, "You know, I watch the games, and even now I never see anyone who reminds me of me, the way I played." Earl is 81 now. I wonder what he thinks about Jalen Brunson.
Lessig: "James Madison, the author of the First Amendment, promised us a Congress “dependent on the people alone,” where by the people, he meant, “not the rich more than the poor.” That his words have been read to produce a government plainly “dependent on” the rich more than the poor is not on him. It is the product of a Court unconstrained by the original meaning of his First Amendment. Whether this Court will remain so unconstrained — whether it will continue to impose its values on the Constitution’s text regardless of the meaning the framers gave to that text—is the most urgent constitutional question on the Supreme Court’s docket." That last link is required reading.