I first heard about the “World Live Web” when my son Allen dropped the phrase casually in conversation, back in 2003. His case was simple: the Web we had then was underdeveloped and inadequate.  Specifically, it was static. Yes, it changed over time, but not in a real-time way. For example, we could search in real time, but search engine indexes were essentially archives, no matter how often they were updated. So it was common for Google’s indexes, even of blogs, to be a day or more old. Technorati, IceRocket, PubSub and other live RSS-fed search engines came along to address that issue, as did Google Blogsearch as well. But they mostly covered blogs and sites with RSS feeds. (Which made sense, since blogs were the most live part of the Web back then. And RSS is still a Live Web thing.)
Specifically, it was static. Yes, it changed over time, but not in a real-time way. For example, we could search in real time, but search engine indexes were essentially archives, no matter how often they were updated. So it was common for Google’s indexes, even of blogs, to be a day or more old. Technorati, IceRocket, PubSub and other live RSS-fed search engines came along to address that issue, as did Google Blogsearch as well. But they mostly covered blogs and sites with RSS feeds. (Which made sense, since blogs were the most live part of the Web back then. And RSS is still a Live Web thing.)
At the time Allen had a company that made live connections between people with questions and people with answers — an ancestor of Quora and @Replyz, basically. The Web wasn’t ready for his idea then, even if the Net was.
The difference between the Web and the Net is still an important one — not only because the Web isn’t fully built out (and never will be), but because our concept of the Web remains locked inside the conceptual framework of static things called sites, each with its own servers and services.
We do have live workarounds , for example with APIs, which are good for knitting together sites, services and data. But we’re still stuck inside the client-server world of requests and responses, where we — the users — play submissive roles. The dominant roles are played by the sites and site owners. To clarify this, consider your position in a relationship with a site when you click on one of these:
![]()
Your position is, literally, submissive. You know, like this:
But rather than dwell on client-server design issues, I’d rather look at ways we can break out of the submissive-dominant mold, which I believe we have to do in order for the Live Web to get built out for real. That means not inside anybody’s silo or walled garden.
I’ve written about the Live Web a number of times over the years. This Linux Journal piece in 2005 still does the best job, I think, of positioning the Live Web:
There’s a split in the Web. It’s been there from the beginning, like an elm grown from a seed that carried the promise of a trunk that forks twenty feet up toward the sky.
The main trunk is the static Web. We understand and describe the static Web in terms of real estate. It has “sites” with “addresses” and “locations” in “domains” we “develop” with the help of “architects”, “designers” and “builders”. Like homes and office buildings, our sites have “visitors” unless, of course, they are “under construction”.
One layer down, we describe the Net in terms of shipping. “Transport” protocols govern the “routing” of “packets” between end points where unpacked data resides in “storage”. Back when we still spoke of the Net as an “information highway”, we used “information” to label the goods we stored on our hard drives and Web sites. Today “information” has become passé. Instead we call it “content”.
Publishers, broadcasters and educators are now all in the business of “delivering content”. Many Web sites are now organized by “content management systems”.
The word content connotes substance. It’s a material that can be made, shaped, bought, sold, shipped, stored and combined with other material. “Content” is less human than “information” and less technical than “data”, and more handy than either. Like “solution” or the blank tiles in Scrabble, you can use it anywhere, though it adds no other value.
I’ve often written about the problems that arise when we reduce human expression to cargo, but that’s not where I’m going this time. Instead I’m making the simple point that large portions of the Web are either static or conveniently understood in static terms that reduce everything within it to a form that is easily managed, easily searched, easily understood: sites, transport, content.
The static Web hasn’t changed much since the first browsers and search engines showed up. Yes, the “content” we make and ship is far more varied and complex than the “pages” we “authored” in 1996, when we were still guided by Tim Berners-Lee’s original vision of the Web: a world of documents connected by hyperlinks. But the way we value hyperlinks hasn’t changed much at all. In fact, it was Sergey Brin’s and Larry Page’s insights about the meaning of links that led them to build Google: a search engine that finds what we want by giving maximal weighting to sites with the most inbound links from other sites that have the most inbound links. Although Google’s PageRank algorithm now includes many dozens of variables, its founding insight has proven extremely valid and durable. Links have value. More than anything else, this accounts for the success of Google and the search engines modeled on it.
Among the unchanging characteristics of the static Web is its nature as a haystack. The Web does have a rudimentary directory with the Domain Name Service (DNS), but beyond that, everything to the right of the first single slash is a big “whatever”. UNIX paths (/whatever/whatever/whatever/) make order a local option of each domain. Of all the ways there are to organize things—chronologically, alphabetically, categorically, spatially, geographically, numerically—none prevails in the static Web. Organization is left entirely up to whoever manages the content inside a domain. Outside those domains, the sum is a chaotic mass beyond human (and perhaps even machine) comprehension.
Although the Web isn’t organized, it can be searched as it is in the countless conditional hierarchies implied by links. These hierarchies, most of them small, are what allow search engines to find needles in the World Wide Haystack. In fact, search engines do this so well that we hardly pause to contemplate the casually miraculous nature of what they do. I assume that when I look up linux journal diy-it (no boolean operators, no quotes, no tricks, just those three words), any of the big search engines will lead me to the columns I wrote on that subject for the January and February 2004 issues of Linux Journal. In fact, they probably do a better job of finding old editorial than our own internal searchware. “You can look it up on Google” is the most common excuse for not providing a search facility for a domain’s own haystack.
I bring this up because one effect of the search engines’ success has been to concretize our understanding of the Web as a static kind of place, not unlike a public library. The fact that the static Web’s library lacks anything resembling a card catalog doesn’t matter a bit. The search engines are virtual librarians who take your order and retrieve documents from the stacks in less time than it takes your browser to load the next page.
In the midst of that library, however, there are forms of activity that are too new, too volatile, too unpredictable for conventional Web search to understand fully. These compose the live Web that’s now branching off the static one.
The live Web is defined by standards and practices that were nowhere in sight when Tim Berners-Lee was thinking up the Web, when the “browser war” broke out between Netscape and Microsoft, or even when Google began its march toward Web search domination. The standards include XML, RSS, OPML and a growing pile of others, most of which are coming from small and independent developers, rather than from big companies. The practices are blogging and syndication. Lately podcasting (with OPML-organized directories) has come into the mix as well.
These standards and practices are about time and people, rather than about sites and content. Of course blogs still look like sites and content to the static Web search engines, but to see blogs in static terms is to miss something fundamentally different about them: they are alive. Their live nature, and their humanity, defines the liveWeb.

This was before Twitter not only made the Web live, but did it in part by tying it to SMS on mobile phones. After all, phones work in the real live world.
Since then we’ve come to expect real-time performance out of websites and services. Search not only needs to be up-to-date, but up-to-now. APIs need to perform in real time. And many do. But that’s not enough. And people get that.
For example, CNN Money has a piece titled Life in 2020: Your smartphone will do your laundry. It’s a good future-oriented piece, but it has two problems that go back to a Static Web view of the world. The first problem is that it sees the future being built by big companies: Ericsson, IBM, Facebook, IBM, Microsoft and Qualcomm. The second problem is that it sees the Web, ideally, as a private thing. There’s no other way to interpret this:
“What we’re doing is creating the Facebook of devices,” said IBM Director of Consumer Electronics Scott Burnett. “Everything wants to be its friend, and then it’s connected to the network of your other device. For instance, your electric car will want to ‘friend’ your electric meter, which will ‘friend’ the electric company.”
Gag me with one of these:

This social shit is going way too far. We don’t need the “Facebook” of anything besides Facebook. In fact, not all of us need it, and that’s how the world should be.
Phil Windley gagged on this too. In A Completely Connected World Depends on Loosely Coupled Architectures, he writes,
This is how these articles always are: “everything will have a network connection” and then they stop. News flash: giving something a network connection isn’t sufficient to make this network of things useful. I’ll admit the “Facebook of things” comment points to a strategy. IBM, or Qualcomm, or ATT, or someone else would love to build a big site that all our things connect to. Imagine being at the center of that. While it might be some IBM product manager’s idea of heaven, it sounds like distopian dyspepsia to me.
Ths reminds me of a May 2001 Scientific American article on the Semantic Web where Tim Berners-Lee, James Hendler, and Ora Lassila give the following scenario:
“The entertainment system was belting out the Beatles’ ‘We Can Work It Out’ when the phone rang. When Pete answered, his phone turned the sound down by sending a message to all the other local devices that had a volume control. His sister, Lucy, was on the line from the doctor’s office: …”
Sound familiar? How does the phone know what devices have volume controls? How does the phone know you want the volume to turn down? Why would you program your phone to turn down the volume on your stereo? Isn’t the more natural place to do that on the stereo? While I love the vision, the implementation and user experience is a nightmare.
The problem with the idea of a big Facebook of Things kind of site is the tight coupling that it implies. I have to take charge of my devices. I have to “friend” them. And remember, these are devices, so I’m going to be doing the work of managing them. I’m going to have to tell my stereo about my phone. I’m going to have to make sure I buy a stereo system that understands the “mute the sound” command that my phone sends. I’m going to have to tell my phone that it should send “mute the sound” commands to the phone and “pause the movie” commands to my DVR and “turn up the lights” to my home lighting system. No thanks.
The reason these visions fall short and end up sounding like nightmares instead of Disneyland is that we have a tough time breaking out of the request-response pattern of distributed devices that we’re all too familiar and comfortable with.
David Weinberger tried to get us uncomfortable early in the last decade, with his book Small Pieces Loosely Joined. One of its points: “The Web is doing more than just speeding up our interactions and communications. It’s threading and weaving our time, and giving us more control over it.” Says Phil,
…the only way these visions will come to pass is with a new model that supports more loosely coupled modes of interaction between the thousands of things I’m likely to have connected.
Consider the preceding scenario from Sir Tim modified slightly.
“The entertainment system was belting out the Beatles’ ‘We Can Work It Out’ when the phone rang. When Pete answered, his phone broadcasts a message to all local devices indicating it has received a call. His stereo responded by turning down the volume. His DVR responded by pausing the program he was watching. His sister, Lucy, …”
In the second scenario, the phone doesn’t have to know anything about other local devices. The phone need only indicate that it has received a call. Each device can interpret that message however it sees fit or ignore it altogether. This significantly reduces the complexity of the overall system because individual devices are loosely coupled. The phone software is much simpler and the infrastructure to pass messages between devices is much less complex than an infrastructure that supports semantic discovery of capabilities and commands.
Events, the messages about things that have happened are the key to this simple, loosely coupled scenario. If we can build an open, ubiquitous eventing protocol similar to the open, ubiquitous request protocol we have in HTTP, the vision of a network of things can come to pass in a way that doesn’t require constant tweaking of connections and doesn’t give any one silo (company) control it. We’ve done this before with the Web. It’s time to do it again with the network of things. We don’t need a Facebook of Things. We need an Internet of Things.
I call this vision “The Live Web.” The term was first coined by Doc Searls’ son Allen to describe a Web where timeliness and context matter as much as relevance. I’m in the middle (literally half done) with a book I’m calling The Live Web: Putting Cloud Computing to Work for People . The book describes how events and event-based systems can more easily create the Internet of Things than the traditional request-response-style of building Web sites. Im excited for it to be done. Look for a summer ublishing date. In the meantime, if you’re interested I’d be happy to get your feedback on what I’ve got so far.
Again, Phil’s whole post is here.
I compiled a list of other posts that deal with various VRM issues, including Live Web ones, at the ProjectVRM blog.
If you know about other Live Web developments, list them below. Here’s the key: They can’t depend on any one company’s server or services. That is, the user — you — have to be the driver, and to be independent. This is not to say there can’t be dependencies. It is to say that we need to build out the Web that David Weinberger describes in Small Pieces. As Dave Winer says in The Internet is for Revolution, don’t just think decentralized. (Or re-decentralized, though that’s a fine thing. As is rebooting.) Think distributed. As I explained last year here,
… the Net is not centralized. It is distributed: a heterarchy rather than a hierarchy. At the most basic level, the Net’s existence relies on protocols rather than on how any .com, .org, .edu or .gov puts those protocols to use.
The Net’s protocols are not servers, clouds, wires, routers or code bases. They are agreements about how data flows to and from any one end point and any other. This makes the Internet a world of endsrather than a world of governments, companies and .whatevers. It cannot be reduced to any of those things, any more than time can be reduced to a clock. The Net is as oblivious to usage as are language and mathematics — and just as supportive of every use to which it is put. And, because of this oblivity, The Net supports all without favor to any.
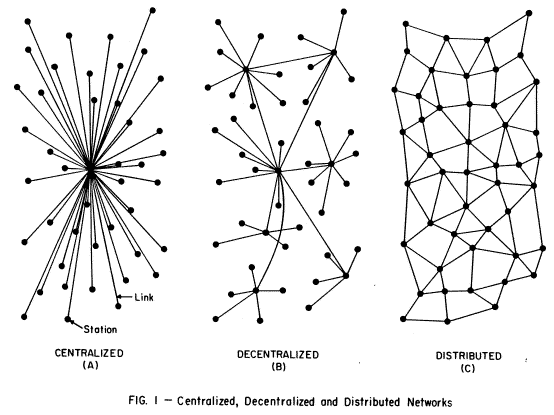
Paul Baran contrasted centralized systems (such as governments), decentralized ones (such as Twitter+Facebook+Google, etc.) and distributed ones, using this drawing in 1964:
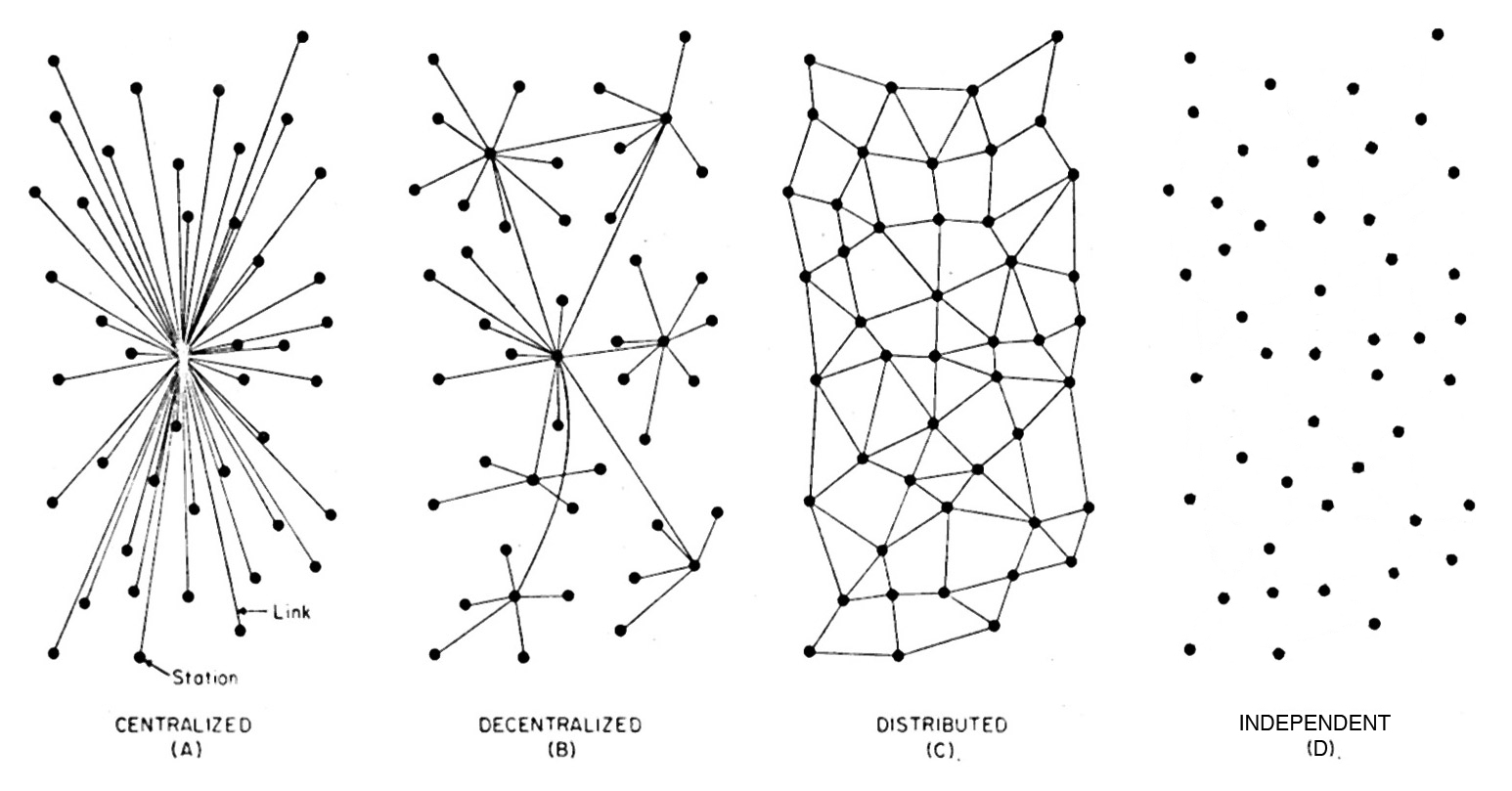
Design C became the Internet. Except the Internet is actually more like D in this version here:
Because on the Internet you don’t have to be connected all the time. And any one node can connect to any other node. Or to many nodes at once. Optionality verges on the absolute.
Time to start living. Not just submitting.
Leave a Reply